
Tag: music
@June 18, 2024 9:30 PM (GMT+2)
音楽生成AIが学習データのどの曲から影響を受けたのかを特定する新しい手法を開発
Choi, Woosung, Junghyun Koo, Kin Wai Cheuk, Joan Serrà, Marco A. Martínez-Ramírez, Yukara Ikemiya, Naoki Murata, Yuhta Takida, Wei-Hsiang Liao, and Yuki Mitsufuji. 2025. "Large-Scale Training Data Attribution for Music Generative Models via Unlearning." arXiv preprint arXiv:2506.18312.
2024
SunoやUdioで生成した楽曲を識別するためのフレームワーク
Rahman, Md Awsafur, Zaber Ibn Abdul Hakim, Najibul Haque Sarker, Bishmoy Paul, and S. Fattah. 2024. “SONICS: Synthetic or Not -- Identifying Counterfeit Songs,” August. http://arxiv.org/abs/2408.14080.

2024
音楽生成AIは学習データをコピーしているだけではないか? 学習データと生成されたデータを比較。
Bralios, Dimitrios, Gordon Wichern, François G. Germain, Zexu Pan, Sameer Khurana, Chiori Hori, and Jonathan Le Roux. 2024. “Generation or Replication: Auscultating Audio Latent Diffusion Models.” In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1156–60. IEEE.

2023
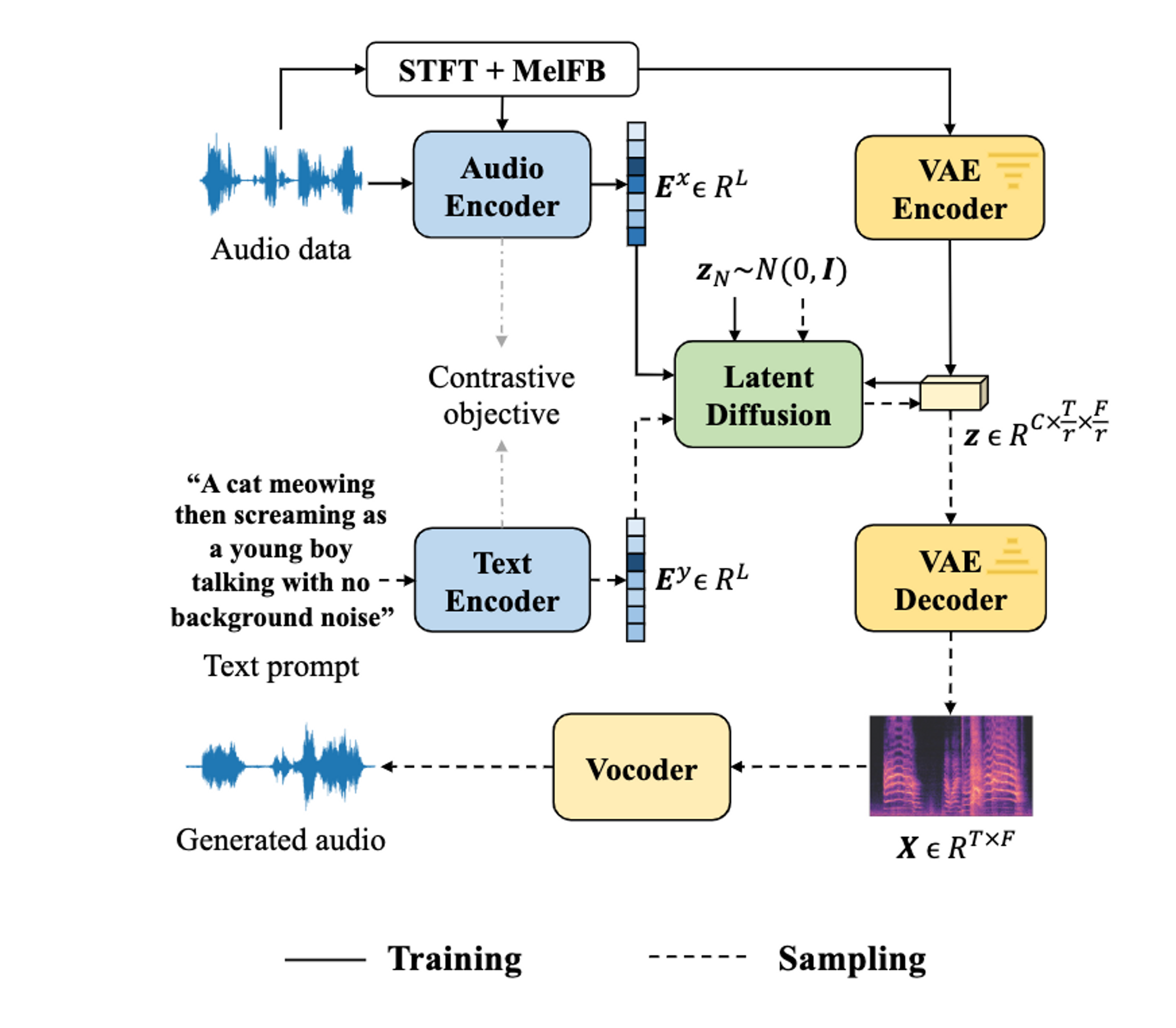
Liu, Haohe, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D. Plumbley. 2023. “AudioLDM: Text-to-Audio Generation with Latent Diffusion Models.” arXiv [cs.SD] . arXiv. http://arxiv.org/abs/2301.12503.
CLAPを用いることでText-to-AudioのSOTAを達成。オープンソース化されていて、すぐに試せるオンラインデモもあり!
2023
音源分離技術を使ってボーカルとそれに付随する伴奏を抽出。その関係を学習。Ground Truth (元々の曲に入ってた伴奏)には流石に劣るがそれに匹敵するクオリティの曲を生成できるようになった。
Donahue, Chris, Antoine Caillon, Adam Roberts, Ethan Manilow, Philippe Esling, Andrea Agostinelli, Mauro Verzetti, et al. 2023. “SingSong: Generating Musical Accompaniments from Singing.” arXiv [cs.SD] . arXiv. http://arxiv.org/abs/2301.12662.

2023
Latent Diffusionのアーキテクチャを利用して、テキストから音楽を生成するモデル
Schneider, Flavio, Zhijing Jin, and Bernhard Schölkopf. 2023. “Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion.” arXiv [cs.CL] . arXiv. http://arxiv.org/abs/2301.11757.

2023
“a calming violin melody backed by a distorted guitar riff” といったテキストから音楽がサウンドファイルとして生成される. Stable Diffusionの音楽版
Agostinelli, Andrea, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, et al. 2023. “MusicLM: Generating Music From Text.” arXiv [cs.SD] . arXiv. http://arxiv.org/abs/2301.11325.
2018
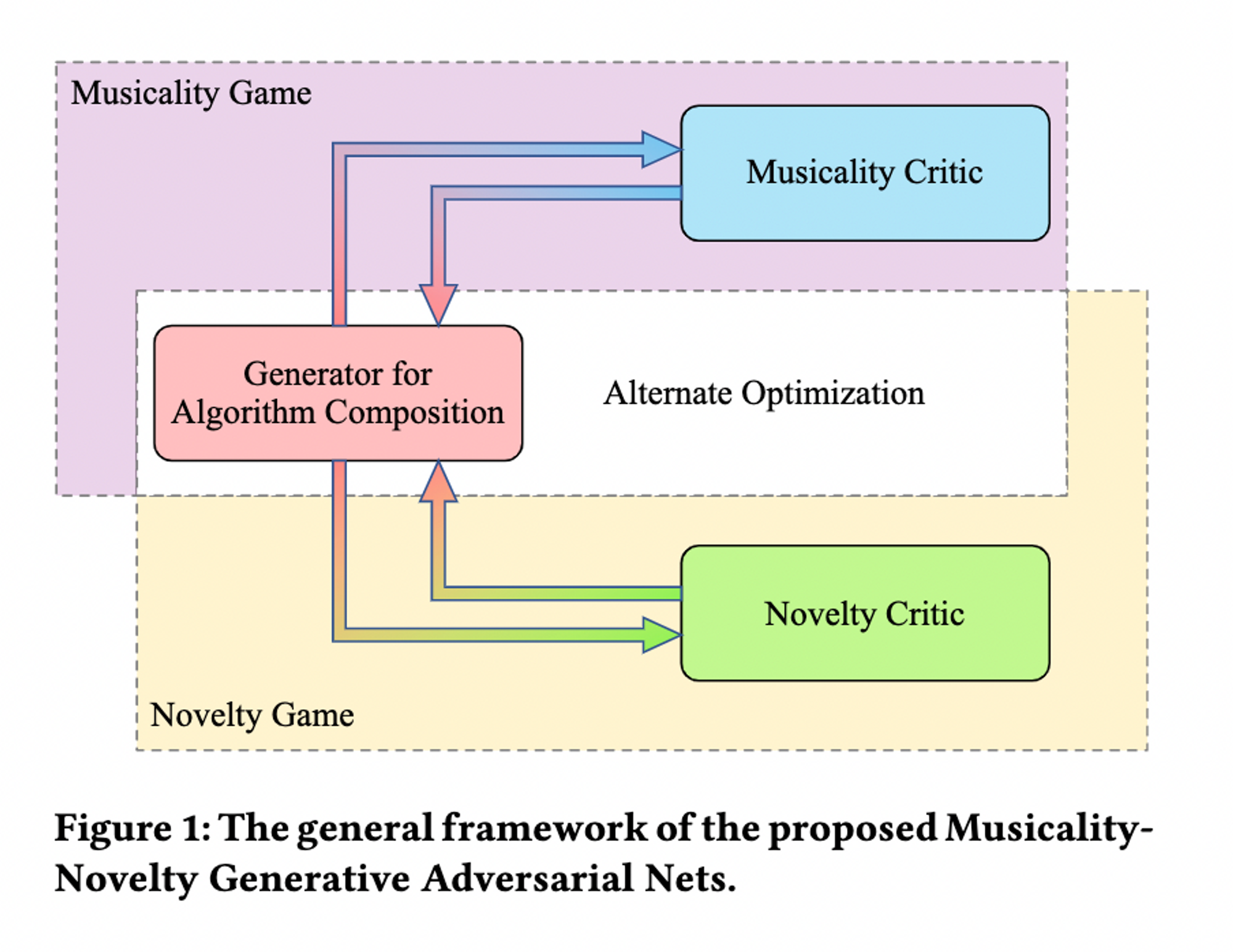
人真似ではない新しい音楽をAIで生成しようとする野心的な研究
Chen, Gong, Yan Liu, Sheng-Hua Zhong, and Xiang Zhang. 2018. “Musicality-Novelty Generative Adversarial Nets for Algorithmic Composition.” In Proceedings of the 26th ACM International Conference on Multimedia , 1607–15. MM ’18. New York, NY, USA: Association for Computing Machinery.

2021
CPUでもサクサク動くのがポイント!
Hayes, B., Saitis, C., & Fazekas, G. (2021). Neural Waveshaping Synthesis.
2021
なんと総時間は約126年分!! データセットを生成するためにpytorch上に実装された、GPUに最適化されたモジュラーシンセ torchsynthも合わせて公開。
Turian, J., Shier, J., Tzanetakis, G., McNally, K., & Henry, M. (2021). One Billion Audio Sounds from GPU-enabled Modular Synthesis.
2020
現代の音楽制作過程で重要なループの組み合わせ。たくさんあるループ間の相性を判定して、適切なループの組み合わせをレコメンドする仕組み。
Chen, B.-Y., Smith, J. B. L. and Yang, Y.-H. (2020) ‘Neural Loop Combiner: Neural Network Models for Assessing the Compatibility of Loops’.

2021
Google Magentaチームの最新のプロジェクト。2020年に発表した DDSP: Differentiable Digital Signal Processing を使って、絵筆のストロークを楽器音に変えている。筆で描くように音を奏でることができる。
Paint with Music - Google Magenta

2020
AI音楽ツールに対する意識調査を117名に対してオンラインで行った。結論からいうと... AIツールはほとんど使われていない。AIツールに対してポジティブな人も、現状ではなく未来の可能性にひかれている。
Knotts, S., & Collins, N. (2020). A survey on the uptake of Music AI Software. Proceedings of the International Conference on New Interfaces for Musical Expression, 594–600.
2020
GANやAutoEncoderが使われている。2021年のアルスエレクトロニカ Digital Musics & Sound Art 部門のゴールデンニカ(最優秀賞)。
Alexander Schubert - Convergence (2020)

2020
少量の学習データでも効率的に学習できるように、最近のダンスミュージックの特徴を生かしたアーキテクチャを採用
Vigliensoni, G., Mccallum, L., & Fiebrink, R. (2020). Creating Latent Spaces for Modern Music Genre Rhythms Using Minimal Training Data. Proc. ICCC 2020.

2021
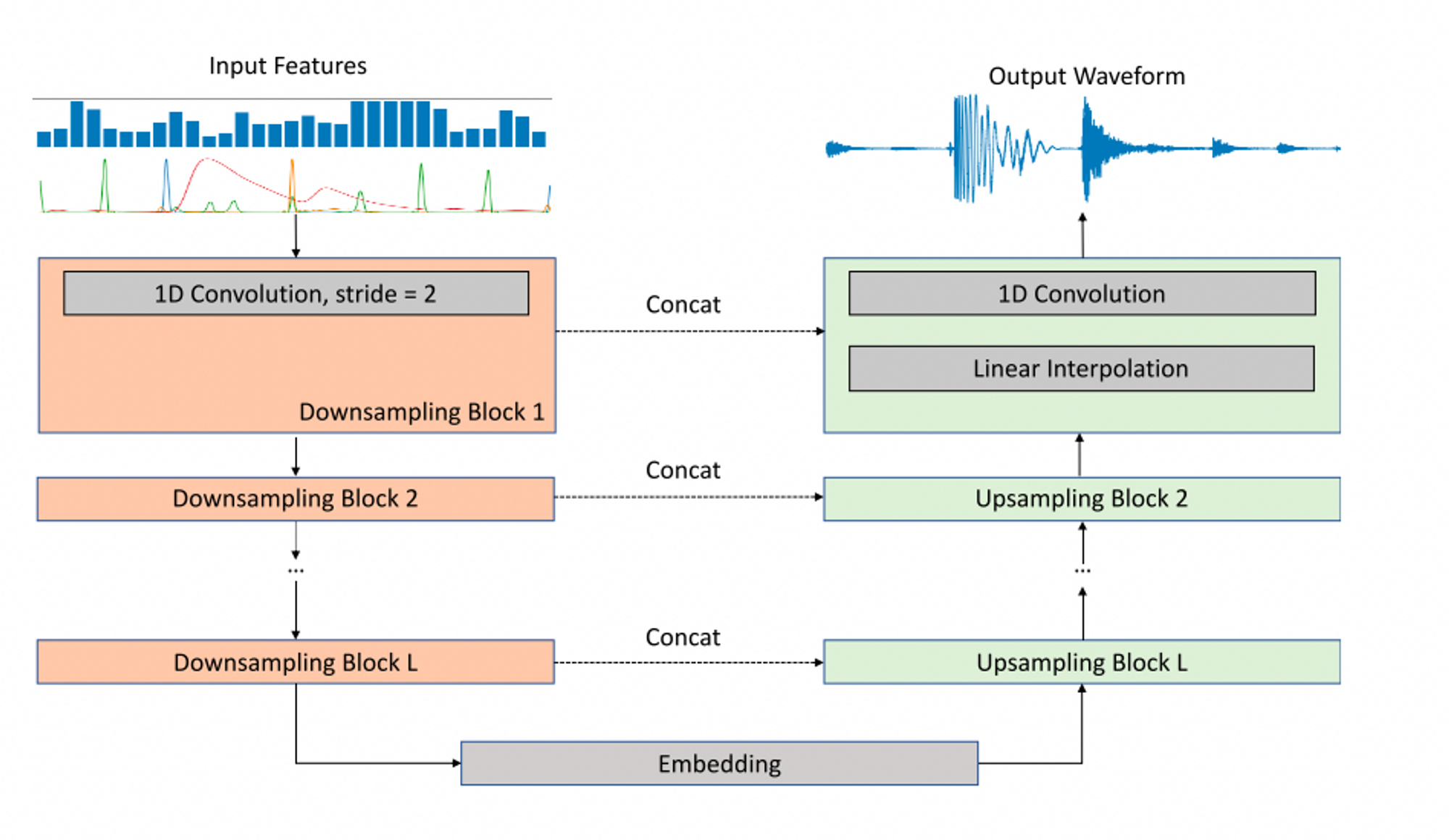
音源分離のモデルで提案されたWave-U-Netのアーキテクチャを用いて、ドラムループをまるごと生成する仕組み
Chandna, P., Ramires, A., Serra, X., & Gómez, E. (2021). LoopNet: Musical Loop Synthesis Conditioned On Intuitive Musical Parameters.
2021
リズムパターンのデータセットもあわせて公開。
Tikhonov, A., & Yamshchikov, I. (2021, July 13). Artificial Neural Networks Jamming on the Beat. 37–44. https://doi.org/10.5220/0010461200370044
.png)
2019
2019年のNIMEで発表された論文。最新の言語モデル(seq-to-seq model)の知見を利用してドラムトラックの音声ファイルからそれにあったベースラインを生成してくれる。
Behzad Haki, & Jorda, S. (2019). A Bassline Generation System Based on Sequence-to-Sequence Learning. Proceedings of the International Conference on New Interfaces for Musical Expression, 204–209.

2017
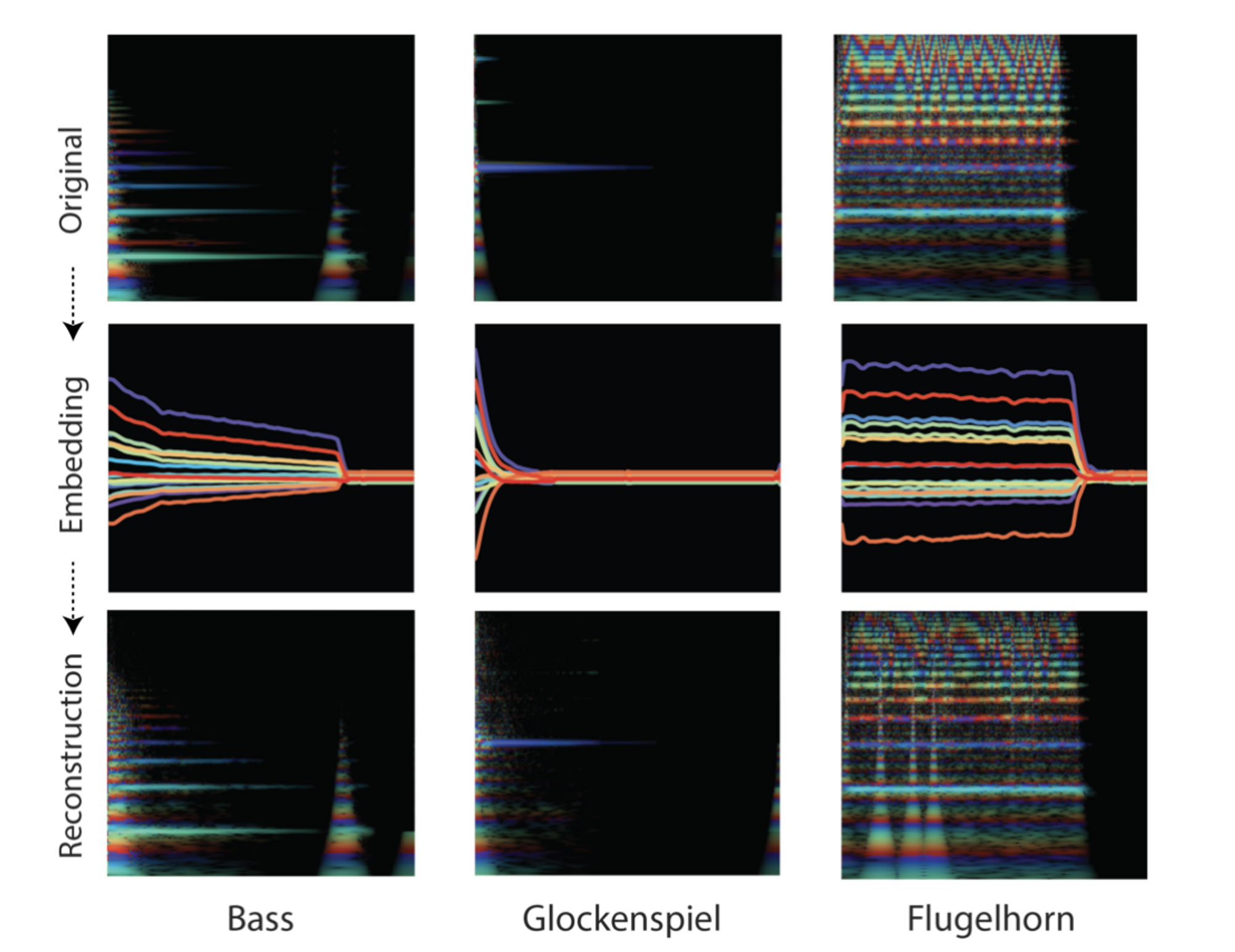
WaveNetの仕組みを使ったAutoencoderで、楽器の音の時間方向の変化も含めて、潜在空間にマッピング → 潜在ベクトルから楽器の音を合成する。この研究で使った多数の楽器の音を集めたデータセット NSynth を合わせて公開。
Engel, J. et al. (2017) ‘Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders’. Available
https://github.com/MTG/essentia
https://github.com/MTG/essentia
Dmitry Bogdanov, et al. 2013. ESSENTIA: an open-source library for sound and music analysis. In Proceedings of the 21st ACM international conference on Multimedia (MM '13). Association for Computing Machinery, New York, NY, USA, 855–858. DOI:https://doi.org/10.1145/2502081.2502229

2020
ドラム、パーカションのワンショットを集めたデータセット
António Ramires, Pritish Chandna, Xavier Favory, Emilia Gómez, & Xavier Serra. (2020). Freesound One-Shot Percussive Sounds (Version 1.0) [Data set]. Zenodo. http://doi.org/10.5281/zenodo.3665275

2021
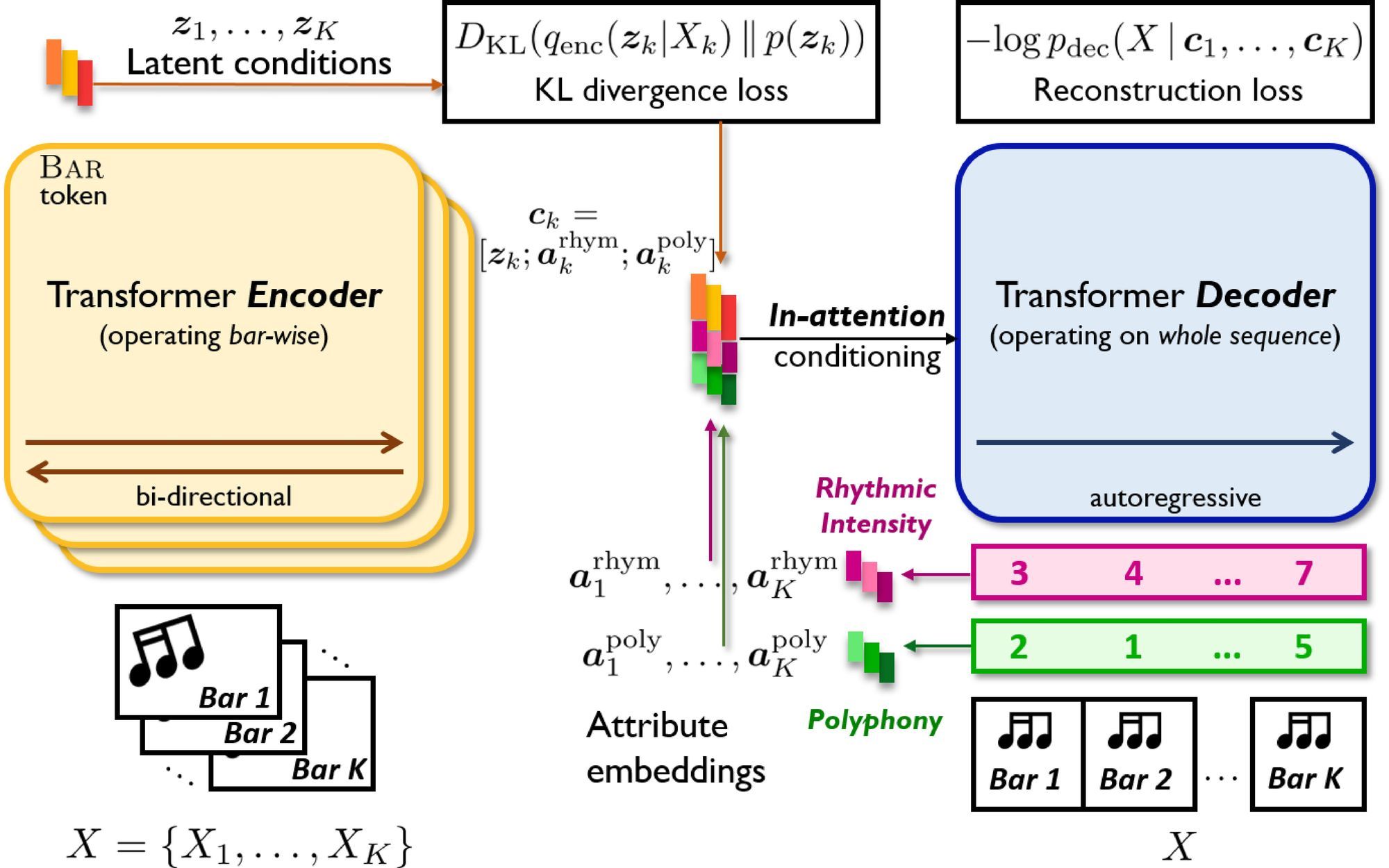
長期の時間依存性を学習できるTransformerの利点とコントロール性が高いVAEの利点。この二つを組み合わせたEncoder-Decoderアーキテクチャで、MIDIで表現された音楽のスタイル変換(Style Transfer)を実現。
Wu, S.-L. and Yang, Y.-H. (2021) ‘MuseMorphose: Full-Song and Fine-Grained Music Style Transfer with Just One Transformer VAE’
2019
スパースなTransformerの仕組みで計算量を抑える
Child, R. et al. (2019) ‘Generating Long Sequences with Sparse Transformers’, arXiv. arXiv. Available at: http://arxiv.org/abs/1904.10509 (Accessed: 29 January 2021).

2020
YouTube上で史上最も多くカバーされた楽曲ビリー・アイリッシュのBad Guy。YouTube上にあがっている曲を解析、分類し、リズムに合わせてスムーズに繋いでいく。無限に続くBad Guyジュークボックス。
Infinite Bad Guy (IYOIYO, Kyle McDonald)

2017
ドラムのキックの位置を入力すると、リズムパターン全体を生成するモデル。言語モデルのseq-to-seqモデルの考え方を利用。
Hutchings, P. (2017). Talking Drums: Generating drum grooves with neural networks.

2021
ベテラン電子音楽家、あのMouse on Marsが、AIを用いたアルバムを公開!! テキストを入力した声を合成するシステムを構築。生成した声を用いて楽曲を構成した。
"AAI" by Mouse on Mars

2020
音楽とアルバムカバーの関係を学習したモデルをベースに、絵画と音楽を相互に変換するパフォーマンス
Verma, P., Basica, C. and Kivelson, P. D. (2020) ‘Translating Paintings Into Music Using Neural Networks’.

2021
Google MagentaのDDSPをリアルタイムに動かせるプラグイン
Francesco Ganis, Erik Frej Knudesn, Søren V. K. Lyster, Robin Otterbein, David Südholt, Cumhur Erkut (2021)

2020
グラニュラーシンセシスのGrain(音の粒)をVAEを使って生成しようという試み。Grainの空間の中での軌跡についても合わせて学習。
Hertzmann, A. (2020) ‘Visual indeterminacy in GAN art’, Leonardo. MIT Press Journals, 53(4), pp. 424–428. doi: 10.1162/LEON_a_01930.

2018
Mor, Noam, et al. "A universal music translation network." arXiv preprint arXiv:1805.07848 (2018).

2019
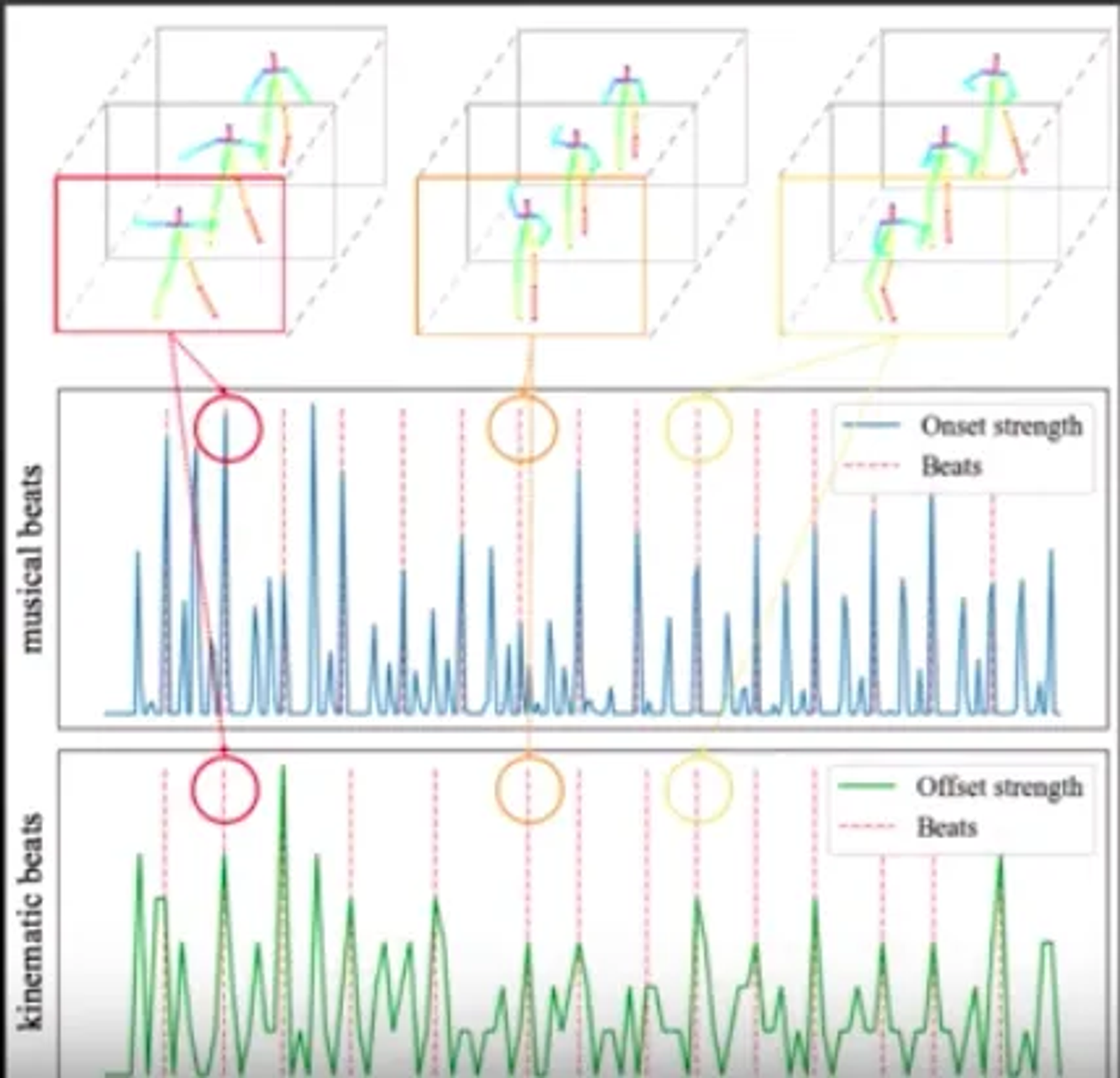
Lee, Hsin-Ying, et al. "Dancing to music." arXiv preprint arXiv:1911.02001 (2019)

Yu, Yi, Abhishek Srivastava, and Simon Canales. "Conditional lstm-gan for melody generation from lyrics." ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) 17.1 (2021): 1-20.

2018
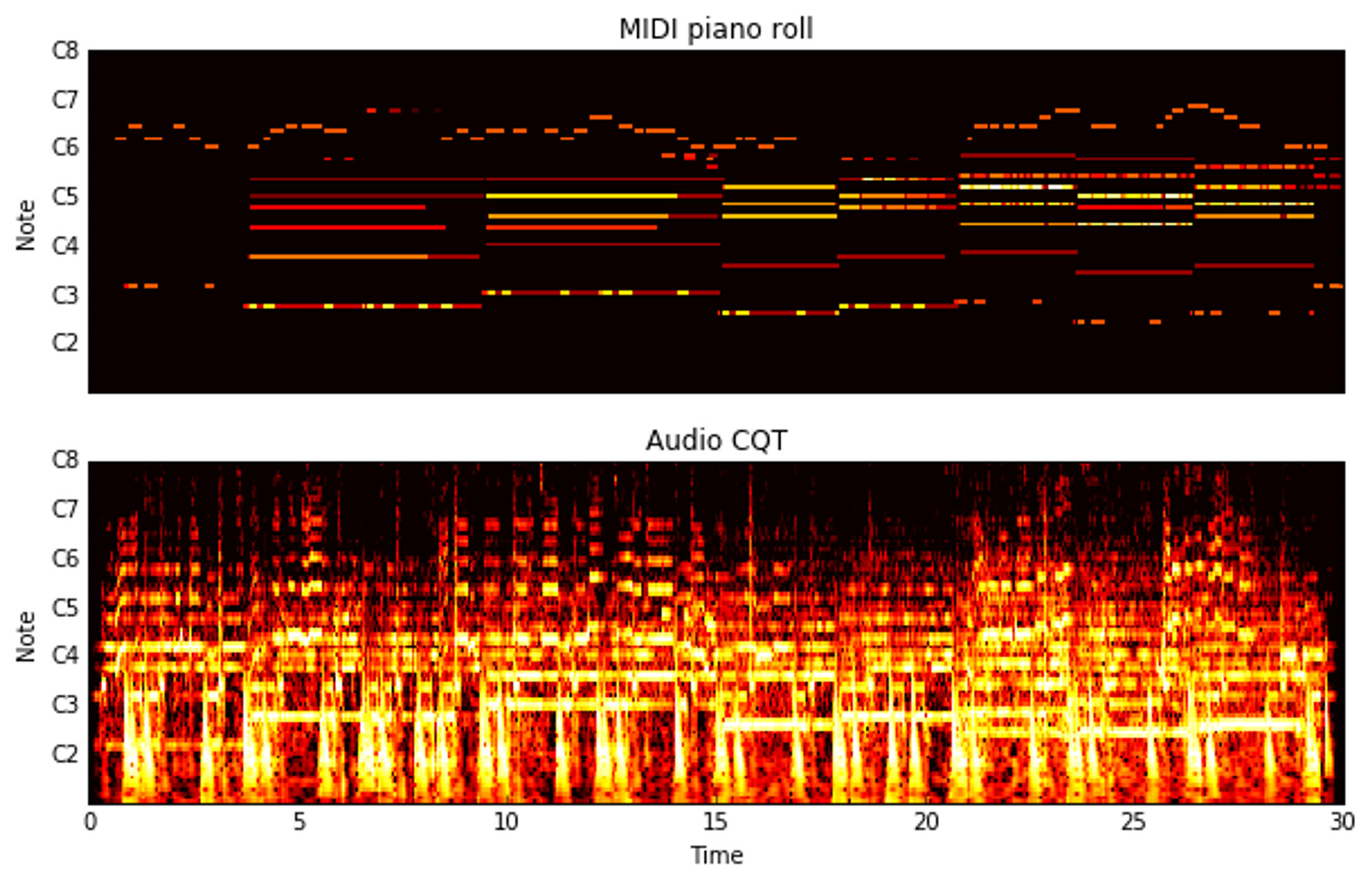
Huang, Sicong, et al. "Timbretron: A wavenet (cyclegan (cqt (audio))) pipeline for musical timbre transfer." arXiv preprint arXiv:1811.09620 (2018).

2019
CDなどのミックスされた音源からボーカル、ピアノ、ベース、ドラムのようにそれぞれの楽器(トラック)の音を抽出できるツール
SPLEETER: A FAST AND STATE-OF-THE ART MUSIC SOURCE SEPARATION TOOL WITH PRE-TRAINED MODELS
2017
Deep Learning Techniques for Music Generation – A Survey

2017
Maison book girl 「cotoeri」

2017
音楽の特徴に基づいたダンスの動きのリアルタイム生成
GrooveNet: Real-Time Music-Driven Dance Movement Generation using Artificial Neural Networks

2017
GANで音楽生成
Yang, Li-Chia, Szu-Yu Chou, and Yi-Hsuan Yang. "Midinet: A convolutional generative adversarial network for symbolic-domain music generation." arXiv preprint arXiv:1703.10847 (2017).

2017
Performance RNN: Generating Music with Expressive Timing and Dynamics

2017
Musical Novelty Search – Evolutionary Algorithms + Ableton Live

2017
The Infinite Drum Machine : Thousands of everyday sounds, organized using machine learning

2017
CNNとLSTMでダンスダンスレボリューションのステップ譜
DONAHUE, Chris; LIPTON, Zachary C.; MCAULEY, Julian, "Dance dance convolution. In: International conference on machine learning", PMLR, pp. 1039-1048, (2017)



2016
Deep Clustering and Conventional Networks for Music Separation: Stronger Together

2017
AENet: Learning Deep Audio Features for Video Analysis
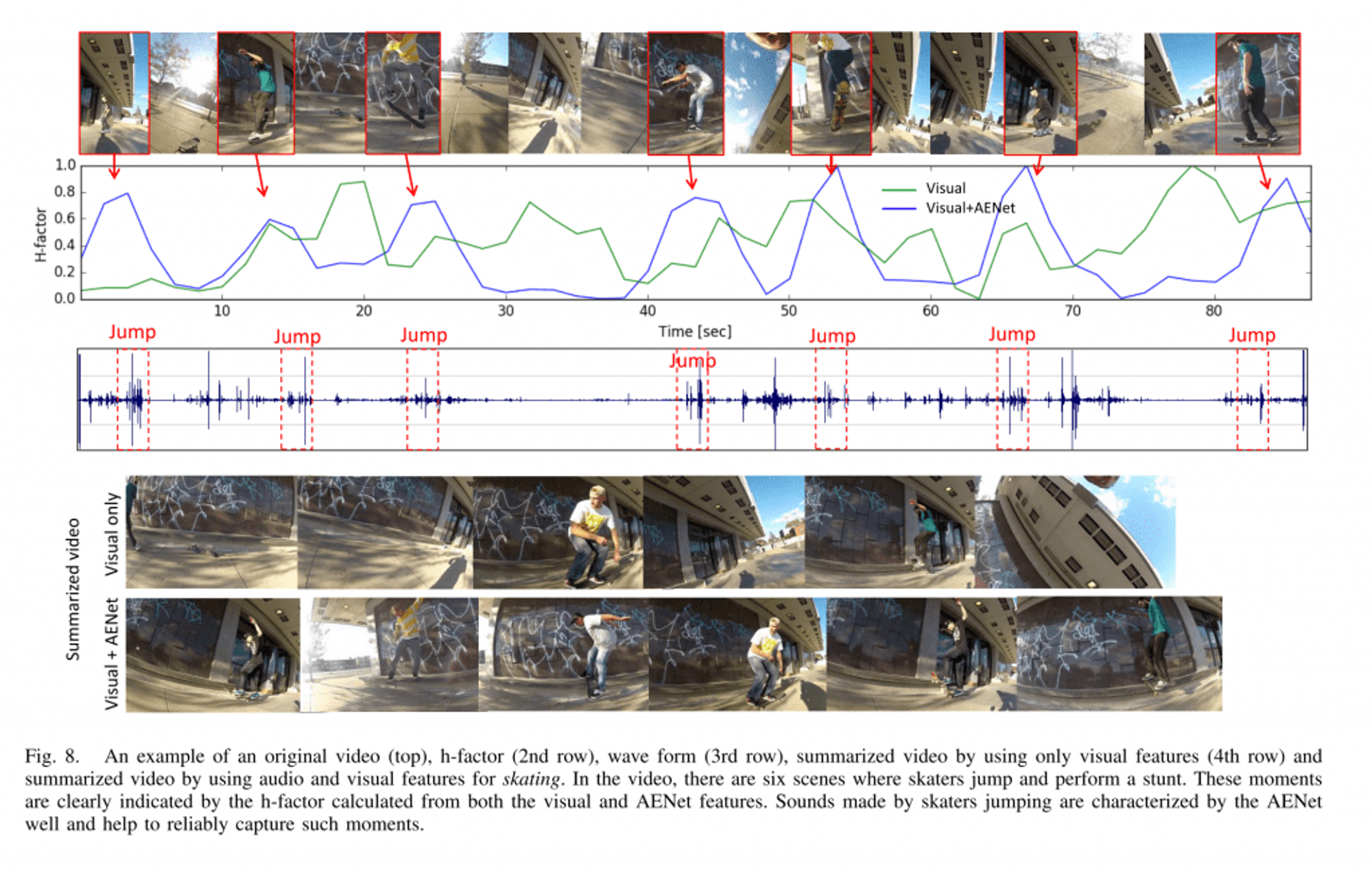
2017
Hadjeres, Gaëtan, François Pachet, and Frank Nielsen, "Deepbach: a steerable model for bach chorales generation.", International Conference on Machine Learning. PMLR, (2017)
2016
Aytar, Yusuf, Carl Vondrick, and Antonio Torralba, "Soundnet: Learning sound representations from unlabeled video.", Advances in neural information processing systems 29, pp892-900 (2016)

