
[Paper]
@June 18, 2024 9:30 PM (GMT+2)
. . "Artists on a Decade of AI Evolution: An Interview Study of Affordances, Culture, and Artistic Practice with Machine Learning."

@June 18, 2024 9:30 PM (GMT+2)
音楽生成AIが学習データのどの曲から影響を受けたのかを特定する新しい手法を開発
Choi, Woosung, Junghyun Koo, Kin Wai Cheuk, Joan Serrà, Marco A. Martínez-Ramírez, Yukara Ikemiya, Naoki Murata, Yuhta Takida, Wei-Hsiang Liao, and Yuki Mitsufuji. 2025. "Large-Scale Training Data Attribution for Music Generative Models via Unlearning." arXiv preprint arXiv:2506.18312.
@June 18, 2024 9:30 PM (GMT+2)
Mo Yu, Lemao Liu, Junjie Wu, Tsz Ting Chung, Shunchi Zhang, Jiangnan Li, Dit-Yan Yeung, Jie Zhou
The Stochastic Parrot on LLM's Shoulder: A Summative Assessment of Physical Concept Understanding
@June 18, 2024 9:30 PM (GMT+2)
Marwa Abdulhai, Isadora White, Yanming Wan, Ibrahim Qureshi, Joel Leibo, Max Kleiman-Weiner, Natasha Jaques
Abdulhai, Marwa, Isadora White, Yanming Wan, Ibrahim Qureshi, Joel Leibo, Max Kleiman-Weiner, and Natasha Jaques. 2026. "How LLMs Distort Our Written Language." arXiv preprint arXiv:2603.18161.
@June 18, 2024 9:30 PM (GMT+2)
Qiawen Ella Liu, Marina Dubova, Henry Conklin, Takumi Harada, Thomas L. Griffiths
Serendipity by Design: Evaluating the Impact of Cross-domain Mappings on Human and LLM Creativity
@June 18, 2024 9:30 PM (GMT+2)
画像認識モデルで誤ってラベル付けされた画像を提示することで、デザイナーに新しいインスピレーションを与えられることを検証
Liu, Fang, Junyan Lv, Shenglan Cui, Zhilong Luan, Kui Wu, and Tongqing Zhou. 2024. “Smart ‘Error’! Exploring Imperfect AI to Support Creative Ideation.” Proceedings of the ACM on Human-Computer Interaction 8 (CSCW1): 1–28.

2024
生成AIをデザインの過程で使うと、AIのアウトプットに無意識に引っ張られてしまい、アイデアの多様性が奪われてしまう可能性がある
Wadinambiarachchi, Samangi, Ryan M. Kelly, Saumya Pareek, Qiushi Zhou, and Eduardo Velloso. 2024. “The Effects of Generative AI on Design Fixation and Divergent Thinking.” arXiv [Cs.HC]. arXiv. http://arxiv.org/abs/2403.11164.

2024
SunoやUdioで生成した楽曲を識別するためのフレームワーク
Rahman, Md Awsafur, Zaber Ibn Abdul Hakim, Najibul Haque Sarker, Bishmoy Paul, and S. Fattah. 2024. “SONICS: Synthetic or Not -- Identifying Counterfeit Songs,” August. http://arxiv.org/abs/2408.14080.

2024
LLMが生成したテキストを学習に利用→新しい学習データを生成→学習を繰り返した結果… Natureに掲載された論文
Shumailov, Ilia, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. 2024. “AI Models Collapse When Trained on Recursively Generated Data.” Nature 631 (8022): 755–59.

2024
アートを含まない学習データを学習したAIモデルをベースに、少数のアート作品の画像でLoRAを学習。きちんとそのアーティストの特徴を掴んだ画像が生成された。
Ren, Hui, Joanna Materzynska, Rohit Gandikota, David Bau, and Antonio Torralba. 2024. “Art-Free Generative Models: Art Creation Without Graphic Art Knowledge.” http://arxiv.org/abs/2412.00176.

2019
Caillon, Antoine, and Philippe Esling. 2021. “RAVE: A Variational Autoencoder for Fast and High-Quality Neural Audio Synthesis.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/2111.05011.

2024
ChatGPTの本質を、哲学者のフランクファートが提唱した概念、「ブルシット=ウンコな議論」を通して捉え直す
Hicks, Michael Townsen, James Humphries, and Joe Slater. 2024. “ChatGPT Is Bullshit.” Ethics and Information Technology 26 (2). https://doi.org/10.1007/s10676-024-09775-5.

2023
LLMと複数の音声合成モデルを駆使して、テキストプロンプトからスピーチ、音楽、SEなどを含む音のコンテンツ(ラジオドラマ、ポッドキャストのようなもの)を生成
Liu, Xubo, Zhongkai Zhu, Haohe Liu, Yi Yuan, Meng Cui, Qiushi Huang, Jinhua Liang, et al. 2023. “WavJourney: Compositional Audio Creation with Large Language Models.” arXiv [cs.SD]. arXiv. http://arxiv.org/abs/2307.14335.

2024
音楽生成AIは学習データをコピーしているだけではないか? 学習データと生成されたデータを比較。
Bralios, Dimitrios, Gordon Wichern, François G. Germain, Zexu Pan, Sameer Khurana, Chiori Hori, and Jonathan Le Roux. 2024. “Generation or Replication: Auscultating Audio Latent Diffusion Models.” In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1156–60. IEEE.

2021
生成モデル(Generative Models)をはじめとするAIモデルの精度が上がる=学習データのパターンをより忠実に再現、再構成できるようになってきた一方で、創造性の観点から言うとそれって学習データものの焼き直しに過ぎないのでは? とう疑問も。 どう適度な逸脱を図るか… が本論文のテーマ。
Broad, Terence, Sebastian Berns, Simon Colton, and Mick Grierson. 2021. “Active Divergence with Generative Deep Learning -- A Survey and Taxonomy.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/2107.05599.

2023
まだチューリング・テストをクリアしているとは言えなそう… 今、テストを実施する意味とは?
Jones, Cameron, and Benjamin Bergen. 2023. “Does GPT-4 Pass the Turing Test?” arXiv [cs.AI]. arXiv. http://arxiv.org/abs/2310.20216.

2023
アーティストのスタイルが勝手に模倣されることを防ぐ Adversarial Example
Shan, Shawn, Jenna Cryan, Emily Wenger, Haitao Zheng, Rana Hanocka, and Ben Y. Zhao. 2023. “GLAZE: Protecting Artists from Style Mimicry by Text-to-Image Models.” arXiv [cs.CR]. arXiv. http://arxiv.org/abs/2302.04222.

2023
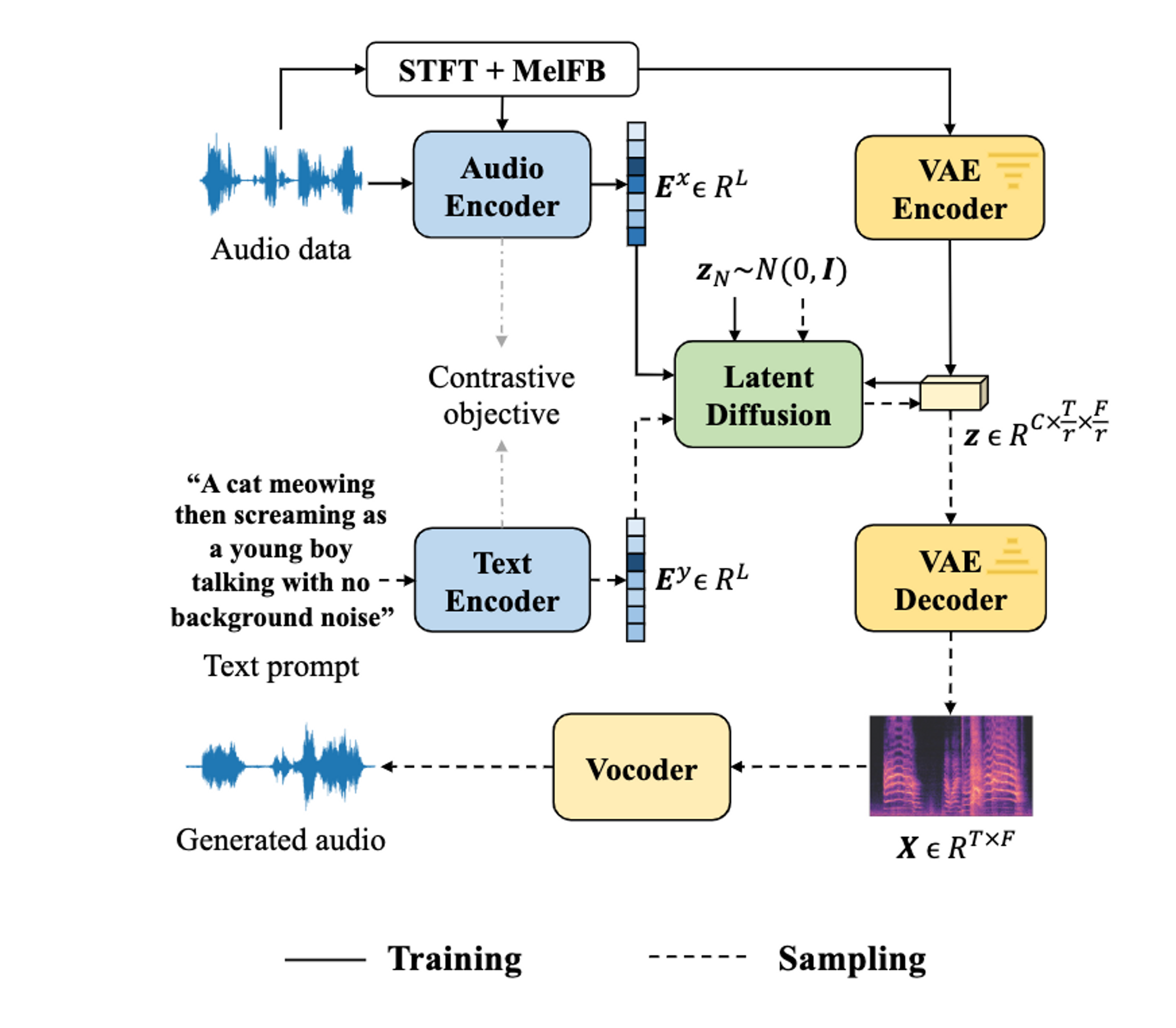
Liu, Haohe, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D. Plumbley. 2023. “AudioLDM: Text-to-Audio Generation with Latent Diffusion Models.” arXiv [cs.SD] . arXiv. http://arxiv.org/abs/2301.12503.
CLAPを用いることでText-to-AudioのSOTAを達成。オープンソース化されていて、すぐに試せるオンラインデモもあり!
2023
音源分離技術を使ってボーカルとそれに付随する伴奏を抽出。その関係を学習。Ground Truth (元々の曲に入ってた伴奏)には流石に劣るがそれに匹敵するクオリティの曲を生成できるようになった。
Donahue, Chris, Antoine Caillon, Adam Roberts, Ethan Manilow, Philippe Esling, Andrea Agostinelli, Mauro Verzetti, et al. 2023. “SingSong: Generating Musical Accompaniments from Singing.” arXiv [cs.SD] . arXiv. http://arxiv.org/abs/2301.12662.

2023
Latent Diffusionのアーキテクチャを利用して、テキストから音楽を生成するモデル
Schneider, Flavio, Zhijing Jin, and Bernhard Schölkopf. 2023. “Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion.” arXiv [cs.CL] . arXiv. http://arxiv.org/abs/2301.11757.

2023
“a calming violin melody backed by a distorted guitar riff” といったテキストから音楽がサウンドファイルとして生成される. Stable Diffusionの音楽版
Agostinelli, Andrea, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, et al. 2023. “MusicLM: Generating Music From Text.” arXiv [cs.SD] . arXiv. http://arxiv.org/abs/2301.11325.
2022
データセットの模倣ではない、新奇性の高い出力を生成AIを用いて実現するために、生成した画像をデータセットに追加していくことを繰り返す
Wu, Yusong, Kyle Kastner, Tim Cooijmans, Cheng-Zhi Anna Huang, and Aaron Courville. n.d. “Datasets That Are Not: Evolving Novelty Through Sparsity and Iterated Learning.”

2018
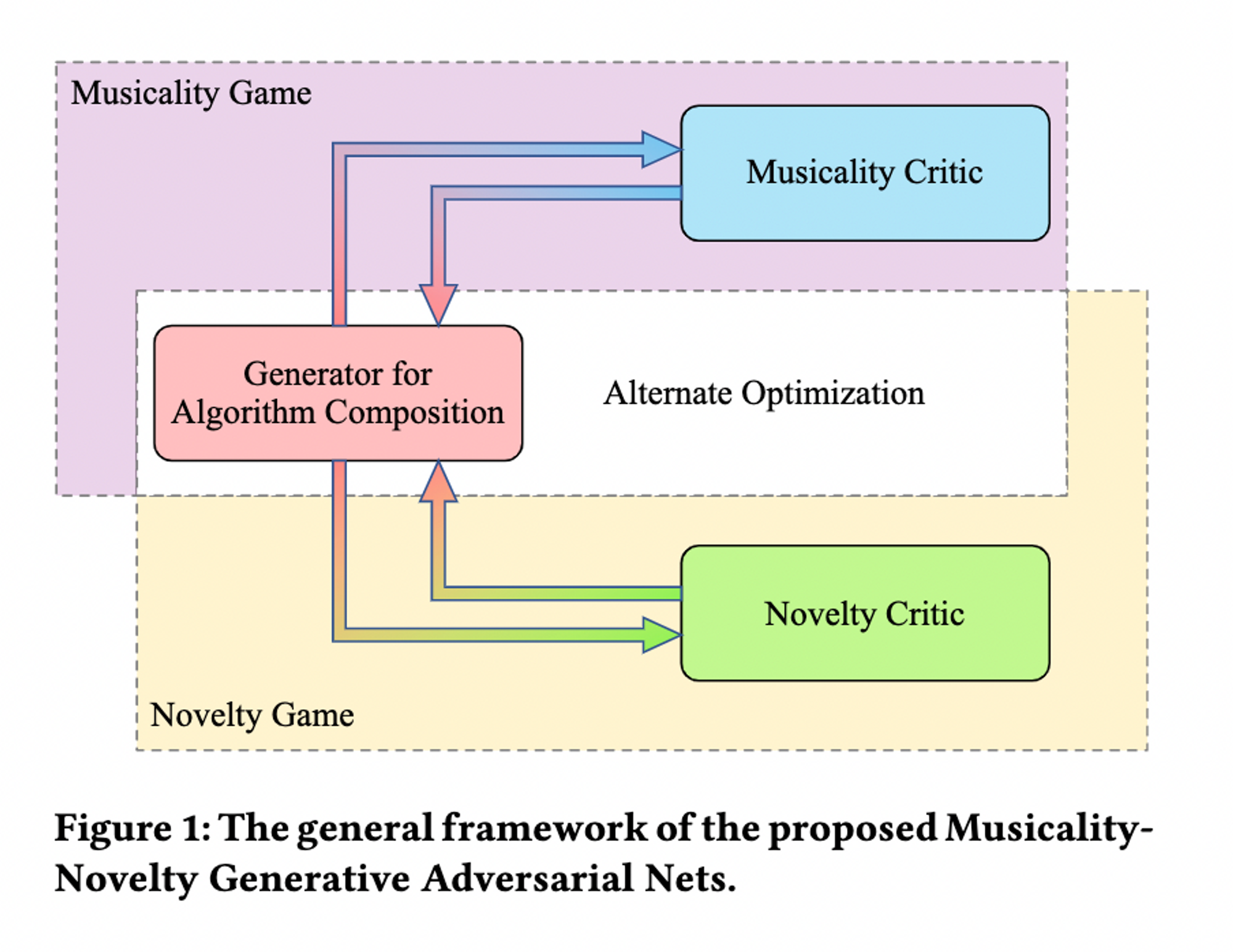
人真似ではない新しい音楽をAIで生成しようとする野心的な研究
Chen, Gong, Yan Liu, Sheng-Hua Zhong, and Xiang Zhang. 2018. “Musicality-Novelty Generative Adversarial Nets for Algorithmic Composition.” In Proceedings of the 26th ACM International Conference on Multimedia , 1607–15. MM ’18. New York, NY, USA: Association for Computing Machinery.

2021
CPUでもサクサク動くのがポイント!
Hayes, B., Saitis, C., & Fazekas, G. (2021). Neural Waveshaping Synthesis.
2019
X線写真をコンテンツ画像に、同時代の同じ作家の絵をスタイル画像としてスタイルトランスファーをかける。美術史家などからその手法に対して強い批判も上がっている。
Bourached, A., & Cann, G. H. (2019). Raiders of the Lost Art. CrossTalk, 22(7–8), 35. https://doi.org/10.1525/9780520914957-028

2021
CLIPからオーディオ表現を抽出する手法であるWav2CLIPを提案。オーディオ分類・検索タスクで良好な結果を残す

2020
現代の音楽制作過程で重要なループの組み合わせ。たくさんあるループ間の相性を判定して、適切なループの組み合わせをレコメンドする仕組み。
Chen, B.-Y., Smith, J. B. L. and Yang, Y.-H. (2020) ‘Neural Loop Combiner: Neural Network Models for Assessing the Compatibility of Loops’.

2020
AI音楽ツールに対する意識調査を117名に対してオンラインで行った。結論からいうと... AIツールはほとんど使われていない。AIツールに対してポジティブな人も、現状ではなく未来の可能性にひかれている。
Knotts, S., & Collins, N. (2020). A survey on the uptake of Music AI Software. Proceedings of the International Conference on New Interfaces for Musical Expression, 594–600.
2019
GPT-2などの言語モデルについて、その精度ではなく、学習時に消費している電力及び、二酸化炭素の放出量についてまとめた。この研究の試算では、例えばTransformer の学習に、一般的な自動車のライフサイクルの約5台分、アメリカ人約17人の一年分に相当するカーボンフットプリントがあることがわかった。
Emma Strubell, Ananya Ganesh, Andrew McCallum (2019)

2020
少量の学習データでも効率的に学習できるように、最近のダンスミュージックの特徴を生かしたアーキテクチャを採用
Vigliensoni, G., Mccallum, L., & Fiebrink, R. (2020). Creating Latent Spaces for Modern Music Genre Rhythms Using Minimal Training Data. Proc. ICCC 2020.

2021
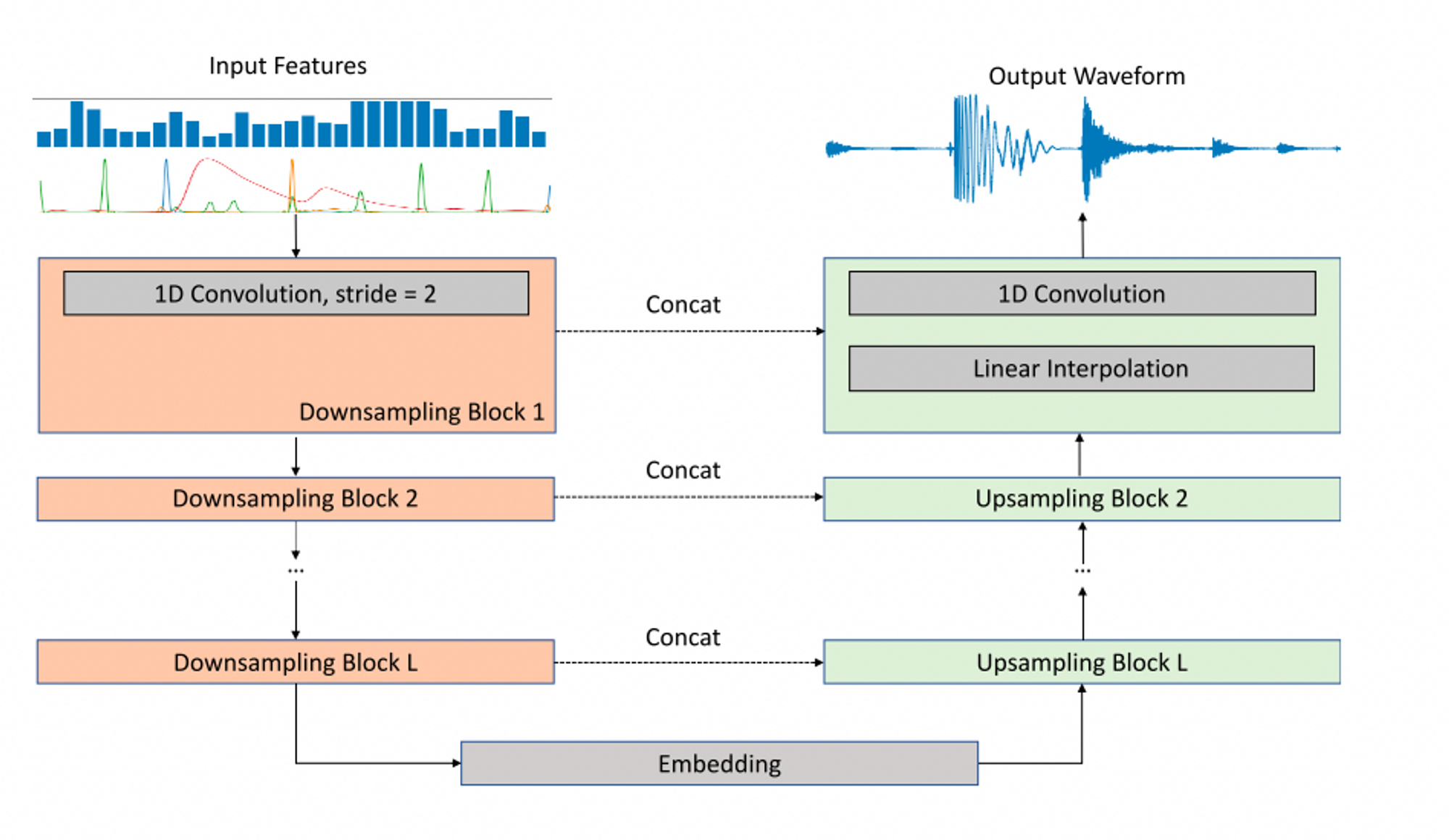
音源分離のモデルで提案されたWave-U-Netのアーキテクチャを用いて、ドラムループをまるごと生成する仕組み
Chandna, P., Ramires, A., Serra, X., & Gómez, E. (2021). LoopNet: Musical Loop Synthesis Conditioned On Intuitive Musical Parameters.
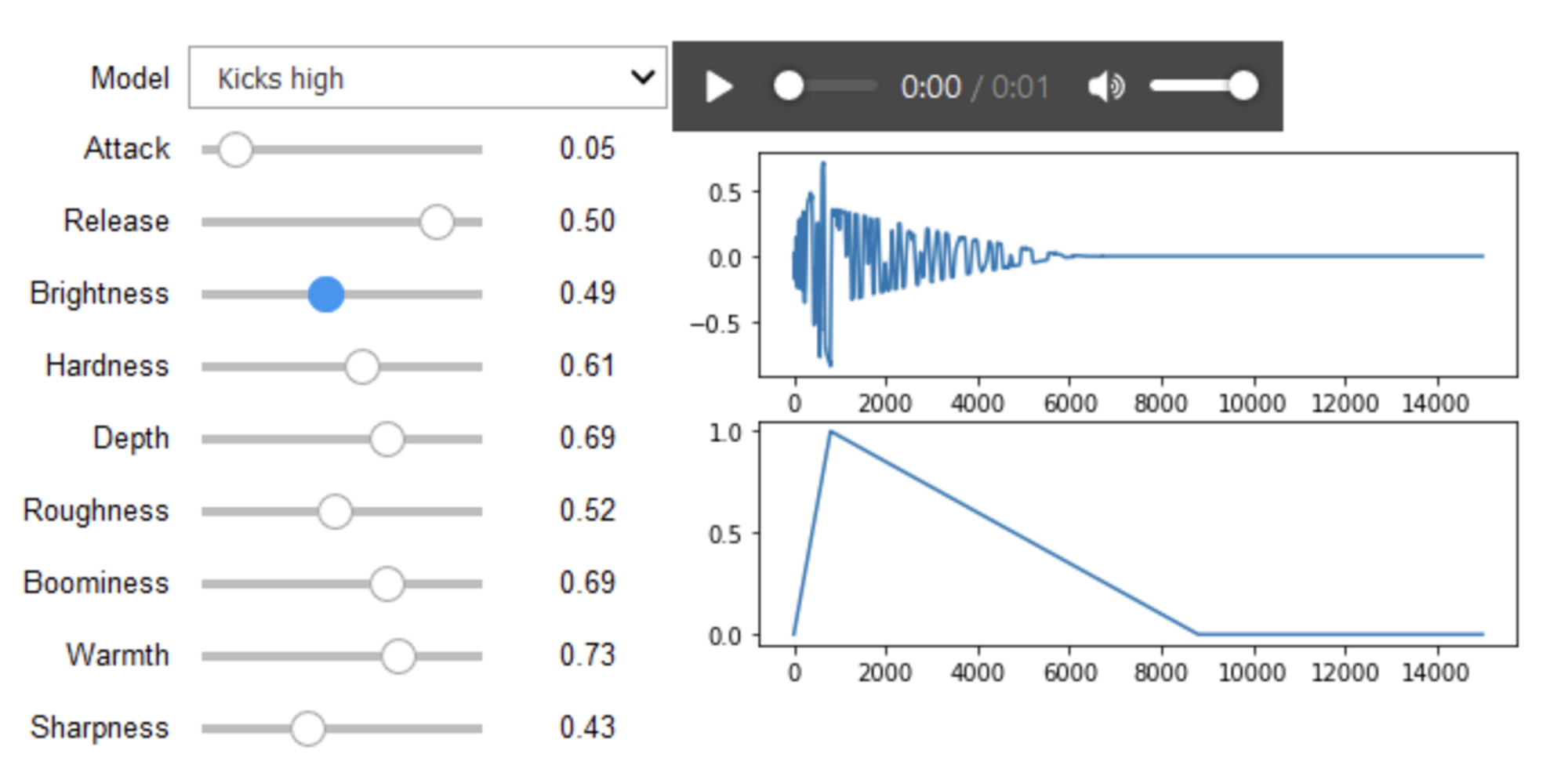
2019
Ramires, A., Chandna, P., Favory, X., Gómez, E., & Serra, X. (2019). Neural Percussive Synthesis Parameterised by High-Level Timbral Features. ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings, 2020-May, 786–790. Retrieved from http://arxiv.org/abs/1911.11853
2020
世界8都市の街中で撮られた動画から顔を抜き出してCNNを用いた感情推定モデルで解析。都市ごとの有意な差は見当たらないという結果に。
Ozakar, R., Gazanfer, R. E., & Sinan Hanay, Y. (2020, November 25). Measuring happiness around the World through artificial intelligence

2021
リズムパターンのデータセットもあわせて公開。
Tikhonov, A., & Yamshchikov, I. (2021, July 13). Artificial Neural Networks Jamming on the Beat. 37–44. https://doi.org/10.5220/0010461200370044
.png)
2019
2019年のNIMEで発表された論文。最新の言語モデル(seq-to-seq model)の知見を利用してドラムトラックの音声ファイルからそれにあったベースラインを生成してくれる。
Behzad Haki, & Jorda, S. (2019). A Bassline Generation System Based on Sequence-to-Sequence Learning. Proceedings of the International Conference on New Interfaces for Musical Expression, 204–209.

2017
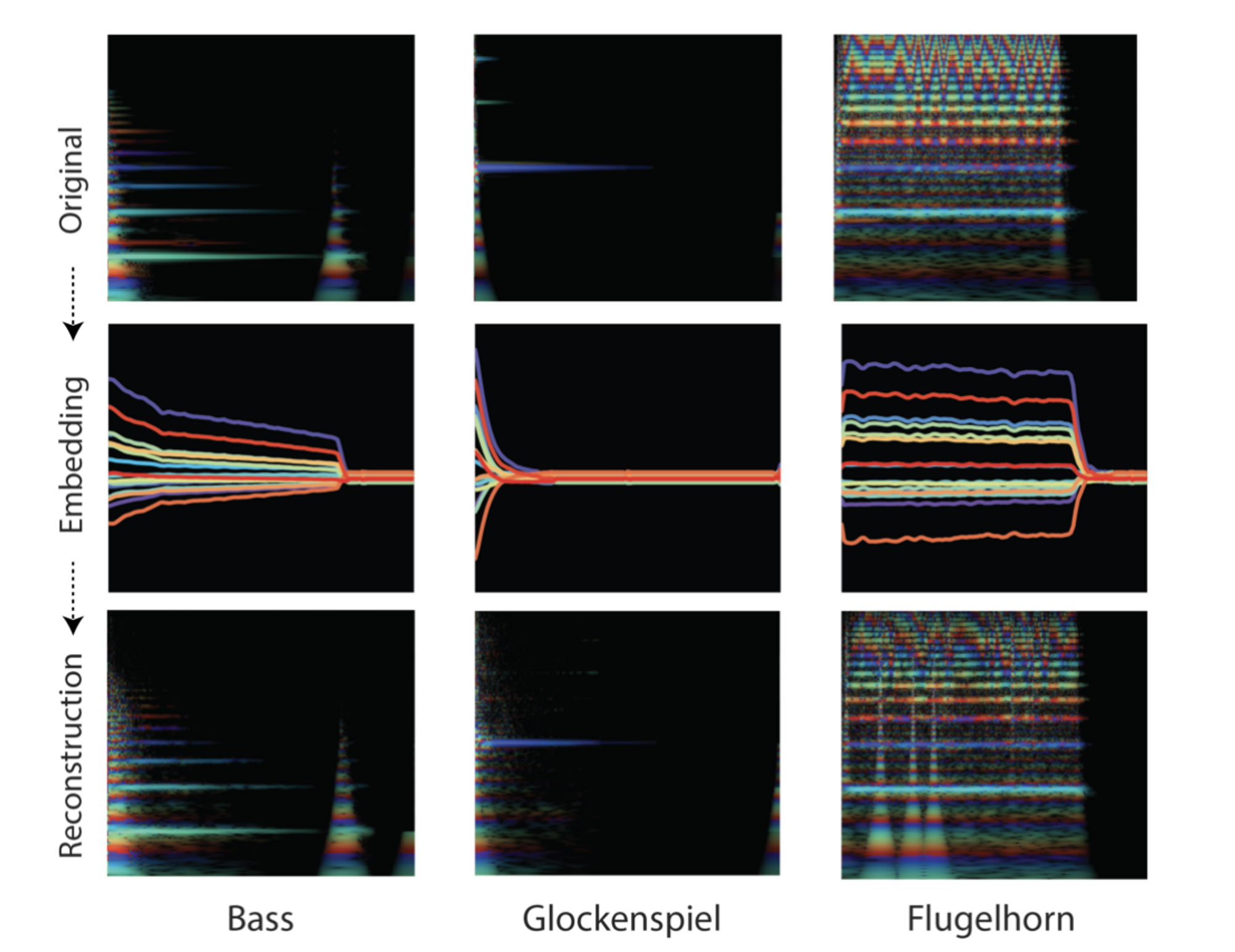
WaveNetの仕組みを使ったAutoencoderで、楽器の音の時間方向の変化も含めて、潜在空間にマッピング → 潜在ベクトルから楽器の音を合成する。この研究で使った多数の楽器の音を集めたデータセット NSynth を合わせて公開。
Engel, J. et al. (2017) ‘Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders’. Available
2021
長期の時間依存性を学習できるTransformerの利点とコントロール性が高いVAEの利点。この二つを組み合わせたEncoder-Decoderアーキテクチャで、MIDIで表現された音楽のスタイル変換(Style Transfer)を実現。
Wu, S.-L. and Yang, Y.-H. (2021) ‘MuseMorphose: Full-Song and Fine-Grained Music Style Transfer with Just One Transformer VAE’
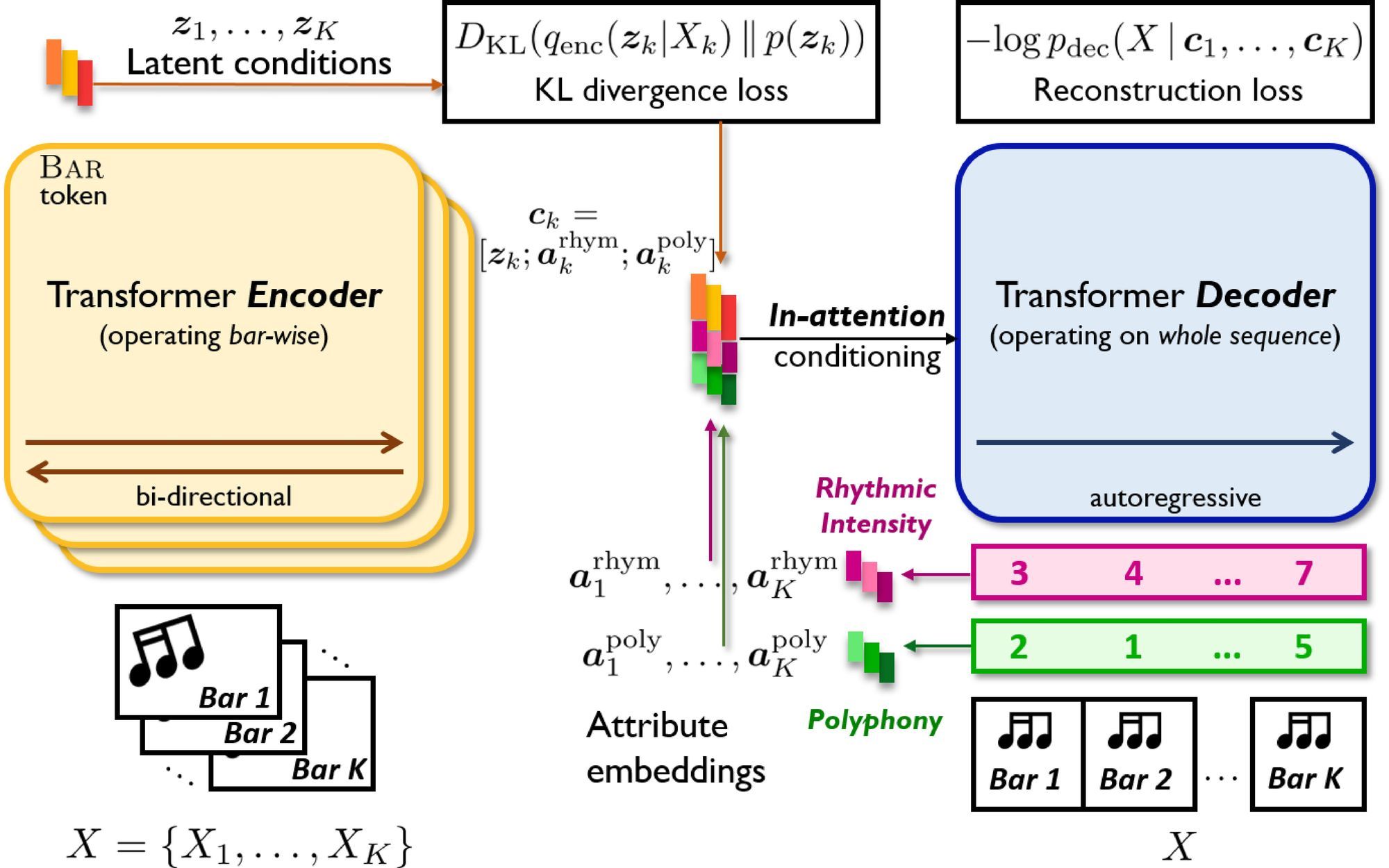
2020
GANが生成する画像の「●●ぽいけど、なんか違う...」という「不確定性」に着目し、現代アートの特徴との比較を行った上で、今後のGANアートの将来像を探る。
Hertzmann, A. (2020) ‘Visual indeterminacy in GAN art’, Leonardo. MIT Press Journals, 53(4), pp. 424–428.

2021
環境音の識別モデルの学習のためのData Augmentation手法の提案
Madhu, A. and K, S. (2021) ‘EnvGAN: Adversarial Synthesis of Environmental Sounds for Data Augmentation’.

2019
スパースなTransformerの仕組みで計算量を抑える
Child, R. et al. (2019) ‘Generating Long Sequences with Sparse Transformers’, arXiv. arXiv. Available at: http://arxiv.org/abs/1904.10509 (Accessed: 29 January 2021).

2019
Likelihoodを最適化しようとすると頻出する単語が必要以上に頻出する結果に
Welleck, S., Kulikov, I., Roller, S., Dinan, E., Cho, K., & Weston, J. (2019). Neural Text Generation with Unlikelihood Training.
.png)
2021
クラウドソーシングの仕組みを活用して、AIが描いた絵を区別できるか、またAIが描いたという情報が、絵自体の評価にどのくらい影響するのかを調査。
Gangadharbatla, H. (2021) ‘The Role of AI Attribution Knowledge in the Evaluation of Artwork’, pp. 1–19. doi: 10.1177/0276237421994697.

2017
ドラムのキックの位置を入力すると、リズムパターン全体を生成するモデル。言語モデルのseq-to-seqモデルの考え方を利用。
Hutchings, P. (2017). Talking Drums: Generating drum grooves with neural networks.

2020
音楽とアルバムカバーの関係を学習したモデルをベースに、絵画と音楽を相互に変換するパフォーマンス
Verma, P., Basica, C. and Kivelson, P. D. (2020) ‘Translating Paintings Into Music Using Neural Networks’.

2021
Google MagentaのDDSPをリアルタイムに動かせるプラグイン
Francesco Ganis, Erik Frej Knudesn, Søren V. K. Lyster, Robin Otterbein, David Südholt, Cumhur Erkut (2021)

2017
現在、GPT-3から音楽生成、画像の生成まで、多様な領域で中心的な仕組みとなっているTransformerを導入した論文。時系列データの学習に一般的に用いられてきたRNNなどの複雑なネットワークを排して、比較的シンプルなAttentionだけで学習できることを示した。
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 2017-Decem, 5999–6009.

2020
グラニュラーシンセシスのGrain(音の粒)をVAEを使って生成しようという試み。Grainの空間の中での軌跡についても合わせて学習。
Hertzmann, A. (2020) ‘Visual indeterminacy in GAN art’, Leonardo. MIT Press Journals, 53(4), pp. 424–428. doi: 10.1162/LEON_a_01930.

2018
Mor, Noam, et al. "A universal music translation network." arXiv preprint arXiv:1805.07848 (2018).

2019
Lee, Hsin-Ying, et al. "Dancing to music." arXiv preprint arXiv:1911.02001 (2019)
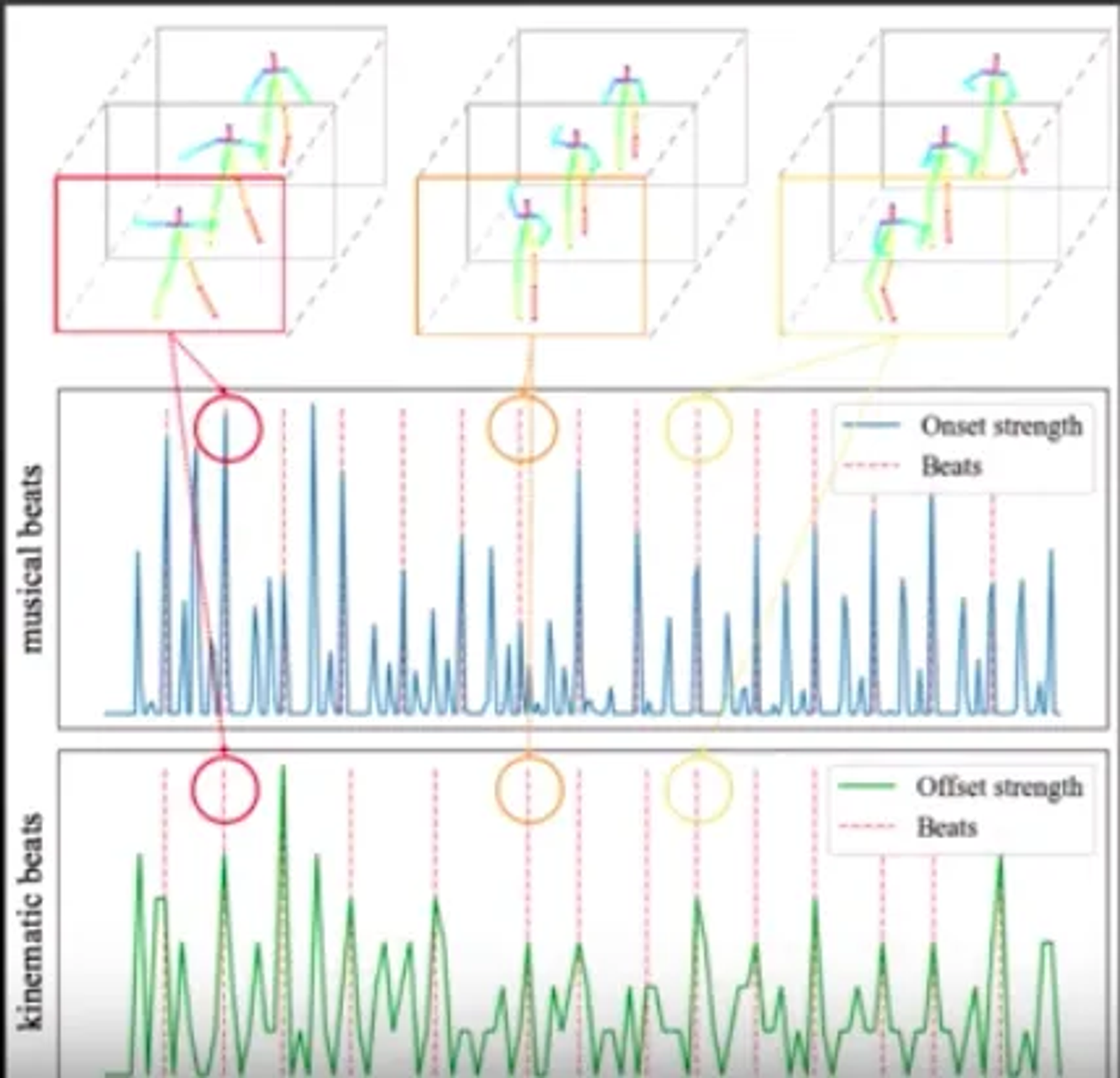
2019
Han-Hung Lee, Da-Gin Wu, and Hwann-Tzong Chen, "Stylizing Audio Reactive Visuals", NeurlPS2019, (2019)


Yu, Yi, Abhishek Srivastava, and Simon Canales. "Conditional lstm-gan for melody generation from lyrics." ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) 17.1 (2021): 1-20.

2019
Tatsuki Koga, at el., "Human and GAN collaboration to create haute couture dress", 33rd Conference on Neural Information Processing Systems, (2019)

2018
Loh, Bryan, and Tom White. "Spacesheets: Interactive latent space exploration through a spreadsheet interface." (2018).

2016
谷口忠大, "記号創発問題: 記号創発ロボティクスによる記号接地問題の本質的解決に向けて (< 特集> 認知科学と記号創発ロボティクス: 実世界情報に基づく知覚的シンボルシステムの構成論的理解に向けて)", 人工知能 Vol.31.1, pp74-81, (2016).
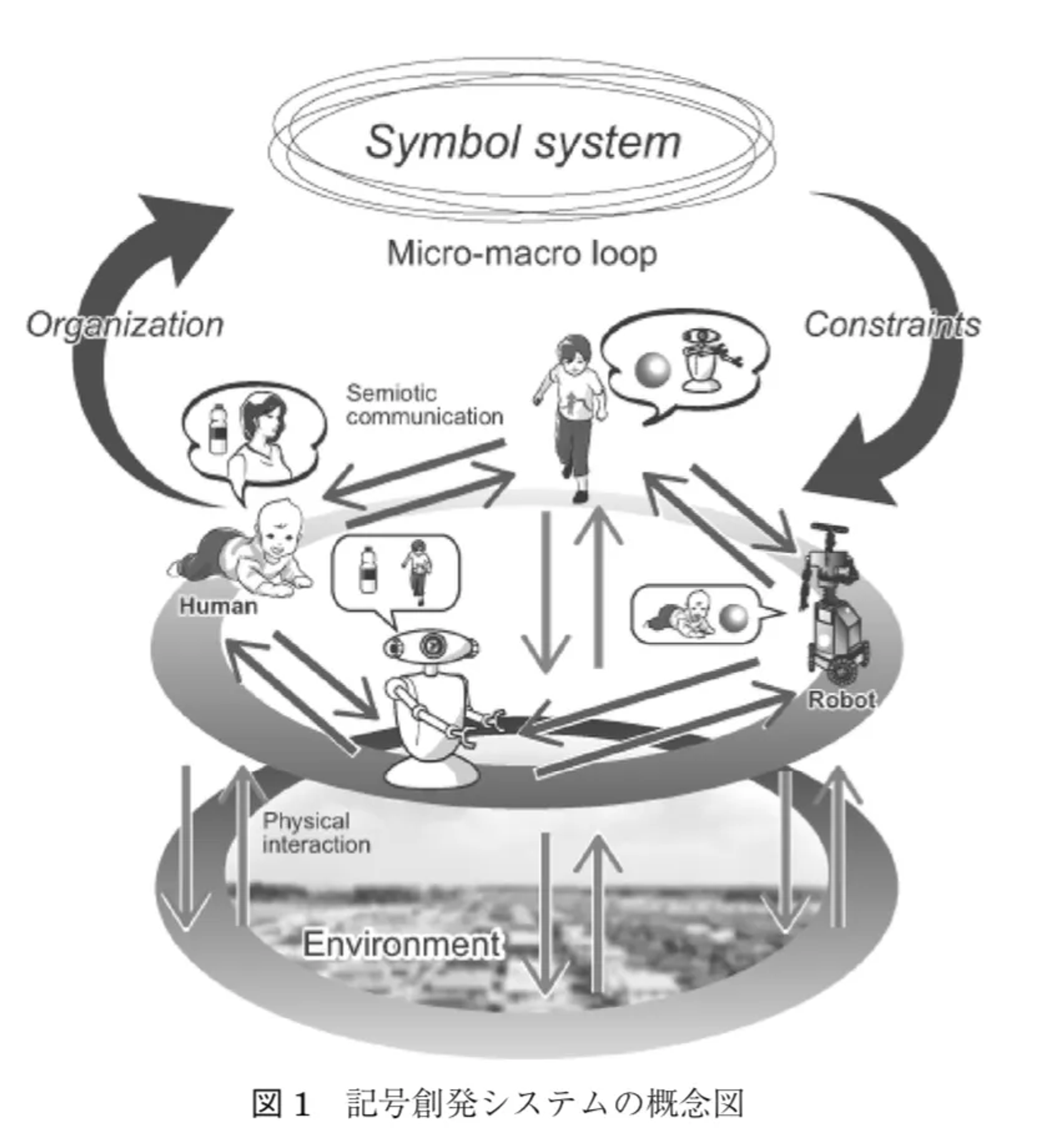
2020
様々なメディアのフレームを補間する – Depth-Aware Video Frame Interpolation
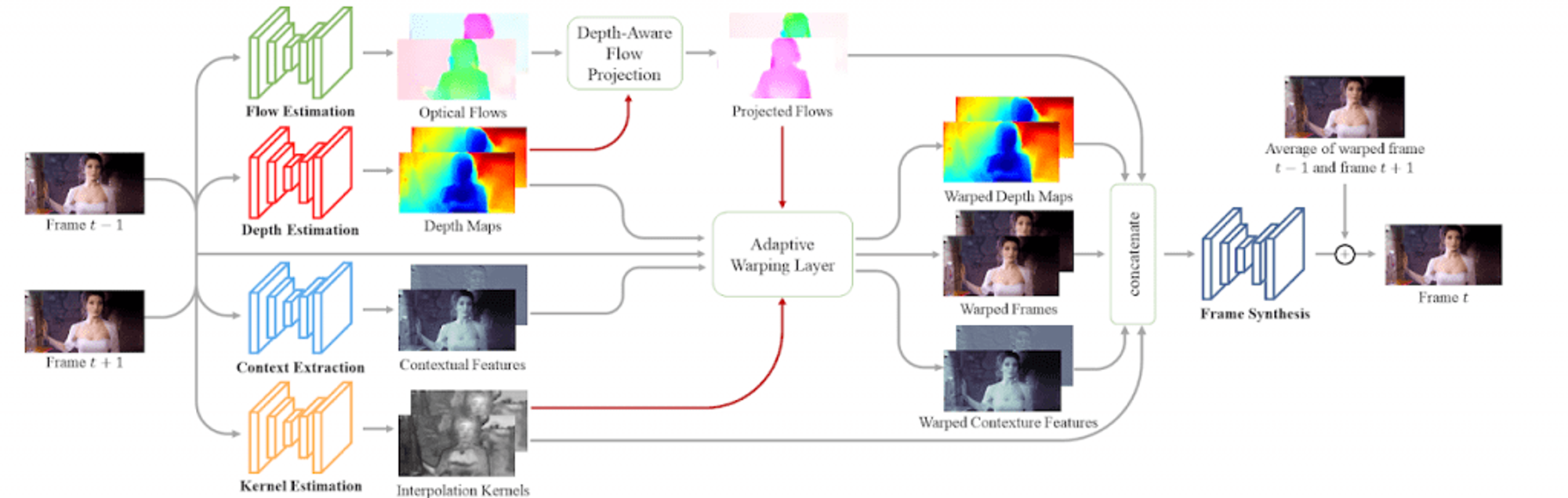
2018
Huang, Sicong, et al. "Timbretron: A wavenet (cyclegan (cqt (audio))) pipeline for musical timbre transfer." arXiv preprint arXiv:1811.09620 (2018).

2019
CDなどのミックスされた音源からボーカル、ピアノ、ベース、ドラムのようにそれぞれの楽器(トラック)の音を抽出できるツール
SPLEETER: A FAST AND STATE-OF-THE ART MUSIC SOURCE SEPARATION TOOL WITH PRE-TRAINED MODELS
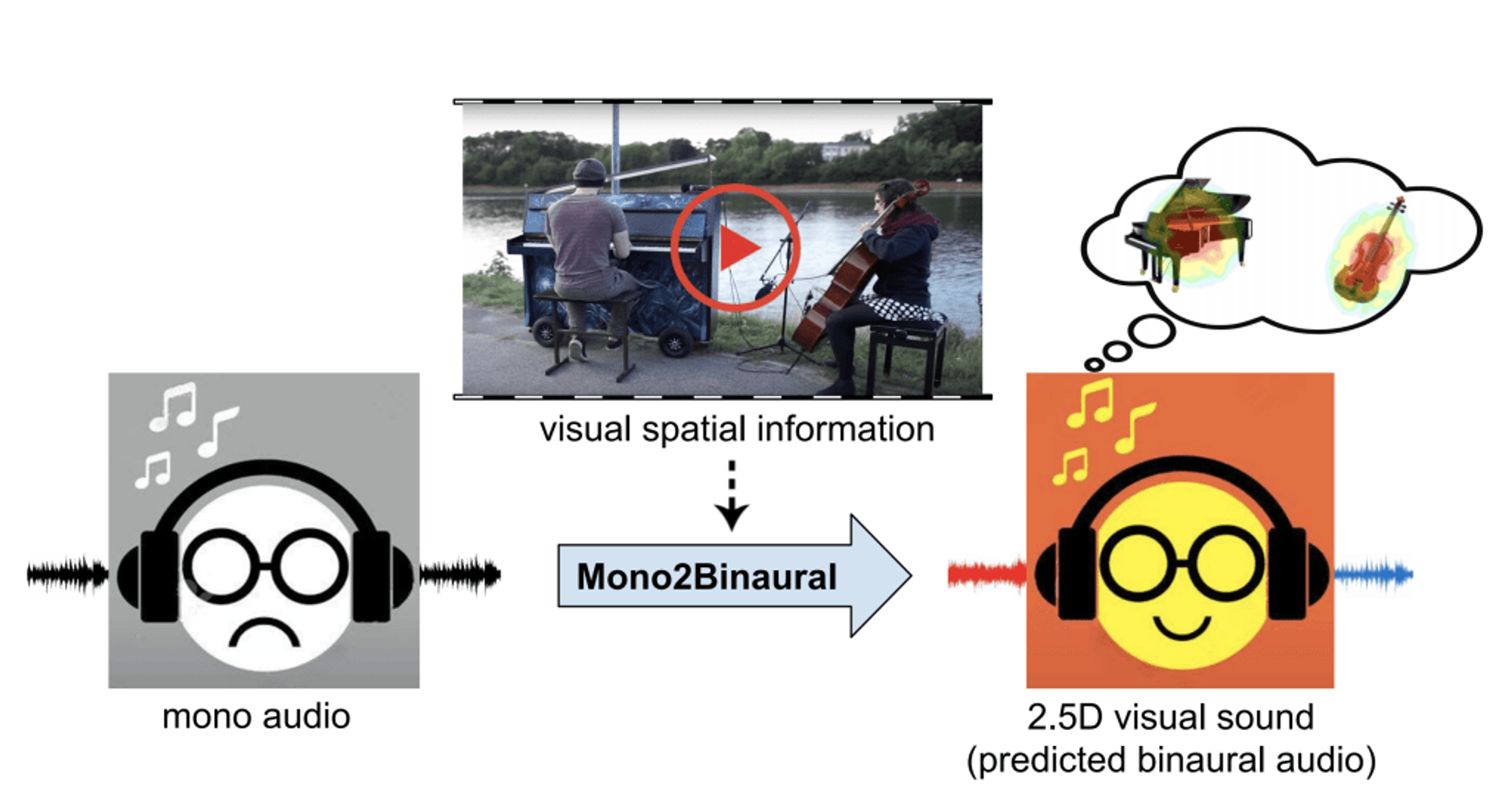
2019
自律型人工アーティストの制作を試みるオープンプレジェクト
Artist in the Cloud: Towards an Autonomous Artist
2018
Audio-Visual Scene Analysis with Self-Supervised Multisensory Features

2020
Lehman, Joel, et al. "The surprising creativity of digital evolution: A collection of anecdotes from the evolutionary computation and artificial life research communities." Artificial life 26.2 (2020): 274-306.

2018
Synthesizing Audio with Generative Adversarial Networks

2018
Visual to Sound: Generating Natural Sound for Videos in the Wild

2017
Neural 3D Mesh Renderer

2017
アフリカの野生動物の観測にDeep Learningを利用 – Automatically identifying wild animals in camera-trap images with deep learning
Automatically identifying wild animals in camera-trap images with deep learning

2017
Deep Learningを活用した都市の”形態学”
Deep Learningを活用した都市の”形態学”

2017
「人間の創造性をどのように評価、定量化するか」という大きな問題に取り組んでいる
A Machine Learning Approach for Evaluating Creative Artifacts

2017
音楽の特徴に基づいたダンスの動きのリアルタイム生成
GrooveNet: Real-Time Music-Driven Dance Movement Generation using Artificial Neural Networks

2017
グラフィックデザインにおける各要素の重要性を可視化
グラフィックデザインにおける各要素の重要性を可視化 – Learning Visual Importance for Graphic Designs and Data Visualizations

2017
GANで音楽生成
Yang, Li-Chia, Szu-Yu Chou, and Yi-Hsuan Yang. "Midinet: A convolutional generative adversarial network for symbolic-domain music generation." arXiv preprint arXiv:1703.10847 (2017).

2017
CAN: Creative Adversarial Networks Generating “Art” by Learning About Styles and Deviating from Style Norms

2017
Chandrasekaran, Arjun, Devi Parikh, and Mohit Bansal. "Punny captions: Witty wordplay in image descriptions." arXiv preprint arXiv:1704.08224 (2017).


2017
Deep Cross-Modal Audio-Visual Generation

2017
See, Hear, and Read: Deep Aligned Representations

2017
Forecasting Human Dynamics from Static Images

2017
AIを言葉でナビして学習 – Beating Atari with Natural Language Guided Reinforcement Learning
AIを言葉でナビして学習 – Beating Atari with Natural Language Guided Reinforcement Learning

2017
Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis

2017
絵を「描く」プロセスの模倣 – A Neural Representation of Sketch Drawings
絵を「描く」プロセスの模倣 – A Neural Representation of Sketch Drawings

2017
Seeing Invisible Poses: Estimating 3D Body Pose from Egocentric Video

2017
Photo Aesthetics Ranking Network with Attributes and Content Adaptation

2017
AutoHair: Fully Automatic Hair Modeling from A Single Image

2017
Using Deep Learning and Google Street View to Estimate the Demographic Makeup of the US

2017
Changing Fashion Cultures

2017
ファッションの地理的および時系列的なトレンドをスナップ写真から解析するプロジェクト.
Abe, Kaori, et al., "Changing fashion cultures." arXiv preprint arXiv:1703.07920, (2017)

2017
CNNとLSTMでダンスダンスレボリューションのステップ譜
DONAHUE, Chris; LIPTON, Zachary C.; MCAULEY, Julian, "Dance dance convolution. In: International conference on machine learning", PMLR, pp. 1039-1048, (2017)

2015
Schifanella, Rossano, Miriam Redi, and Luca Maria Aiello, "An image is worth more than a thousand favorites: Surfacing the hidden beauty of flickr pictures.", Ninth International AAAI Conference on Web and Social Media, (2015)

2017
Using human brain activity to guide machine learning

2017
Deep Photo Style Transfer

2017
Learning to Generate Posters of Scientific Papers

2017
Faster-RCNNの拡張. ひとつのモデルで最小限の変更で物体検出、輪郭検出、人の姿勢の検出を高い精度で行う.
HE, Kaiming, et al., "Mask r-cnn", Proceedings of the IEEE international conference on computer vision, pp. 2961-2969, (2017)

2017
GANを応用したSANによるSaliency Map(顕著性マップ)の生成
GANを応用したSANによるSaliency Map(顕著性マップ)の生成 – Supervised Adversarial Networks for Image Saliency Detection –

2017
機械学習を用いたドローイングツール – AutoDraw
機械学習を用いたドローイングツール – AutoDraw

2016
Domenech, Arnau Pons, and Hartmut Ruhl. "An implicit ODE-based numerical solver for the simulation of the Heisenberg-Euler equations in 3+ 1 dimensions." arXiv preprint arXiv:1607.00253 (2016).

2017
Convolutional Recurrent Neural Networks for Bird Audio Detection

2017
Face-to-BMI: Using Computer Vision to Infer Body Mass Index on Social Media

2017
LIU, Ziwei, et al., "Video frame synthesis using deep voxel flow", Proceedings of the IEEE International Conference on Computer Vision, pp. 4463-4471, (2017)
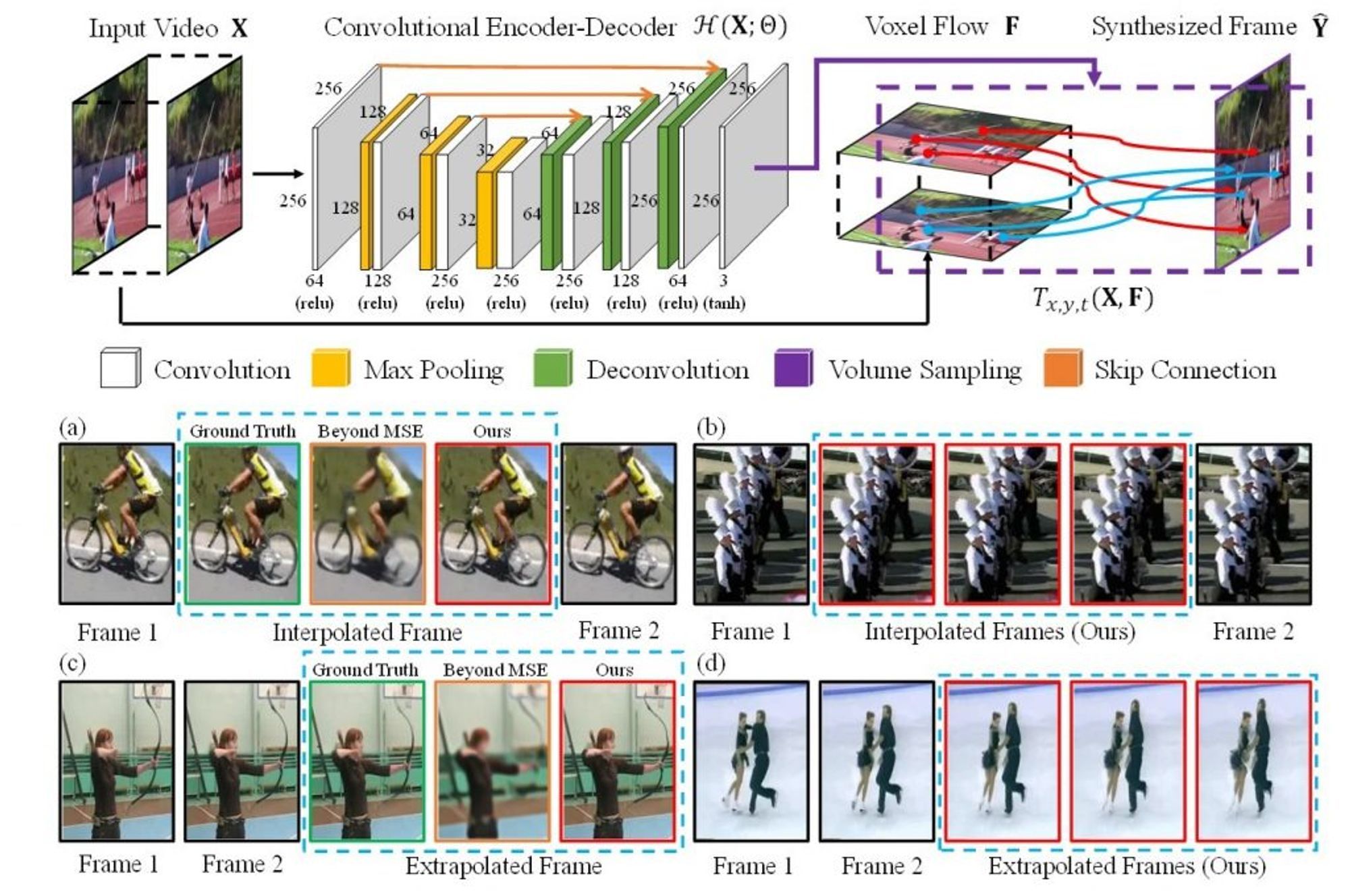
2016
Deep Clustering and Conventional Networks for Music Separation: Stronger Together

2017
YANG, Shuai, et al. "Awesome typography: Statistics-based text effects transfer", Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.7464-7473, (2017)
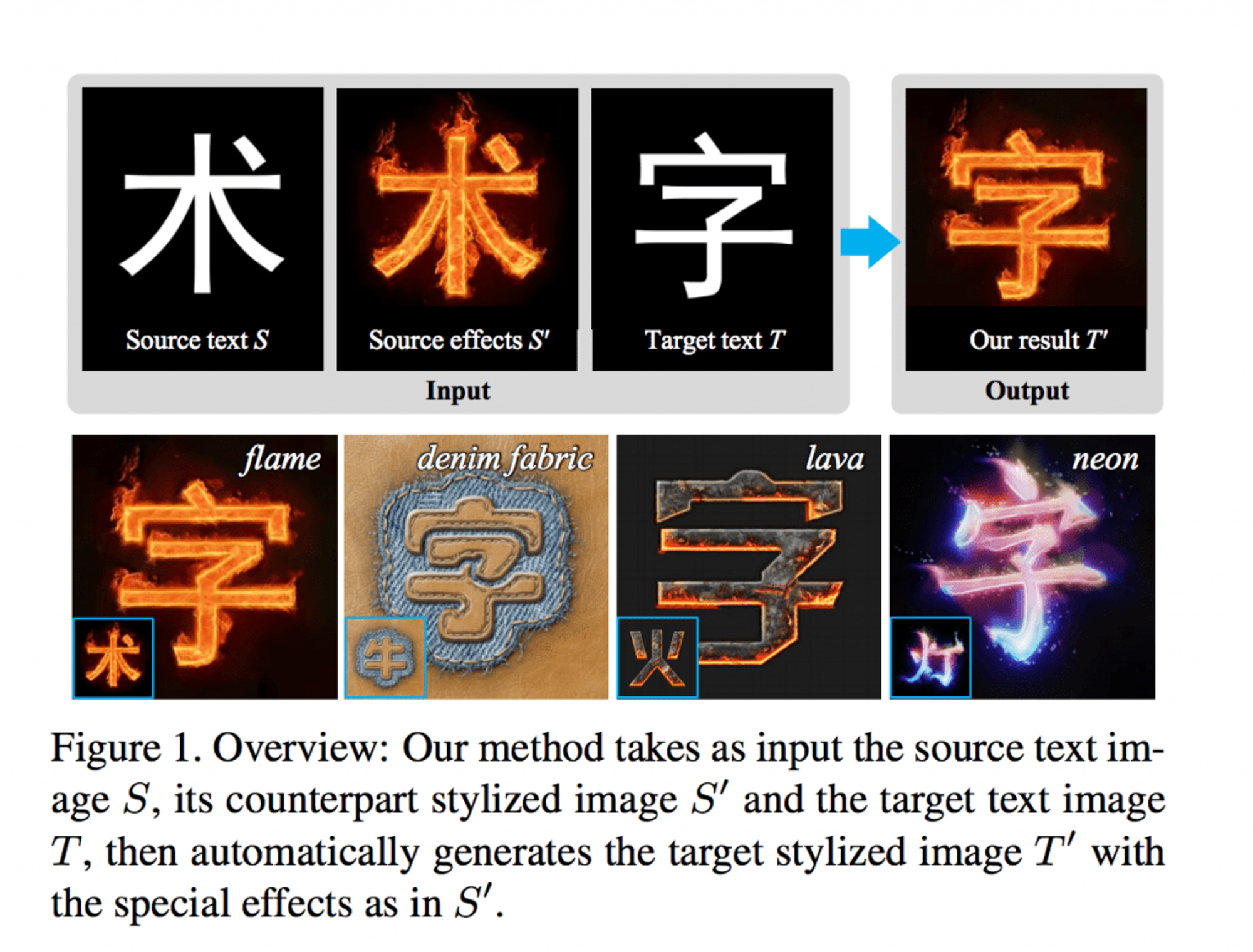
2017
AENet: Learning Deep Audio Features for Video Analysis
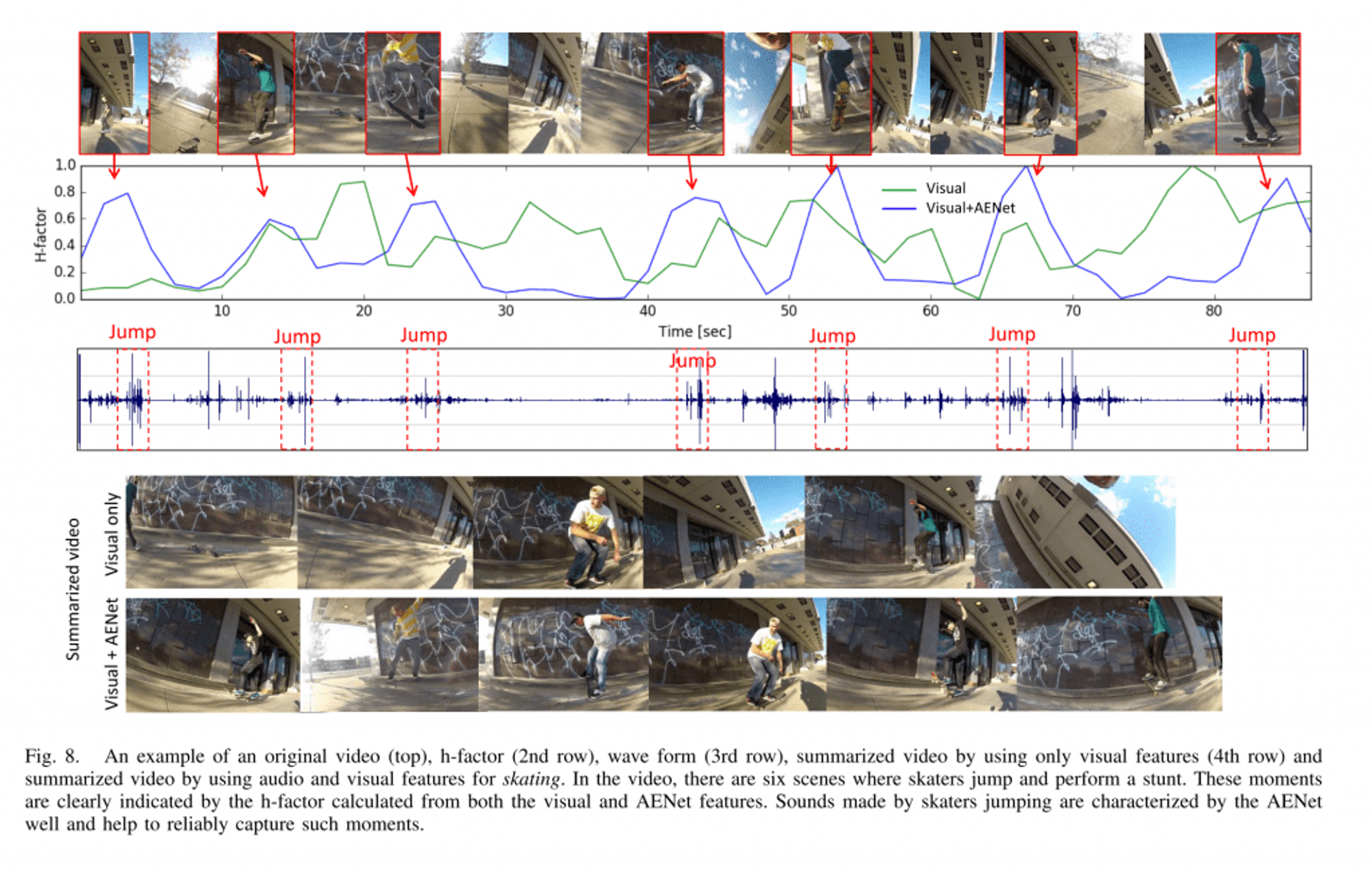
2016
Abadi, Martín, and David G. Andersen. "Learning to protect communications with adversarial neural cryptography." arXiv preprint arXiv:1610.06918 (2016)

2017
Hadjeres, Gaëtan, François Pachet, and Frank Nielsen, "Deepbach: a steerable model for bach chorales generation.", International Conference on Machine Learning. PMLR, (2017)
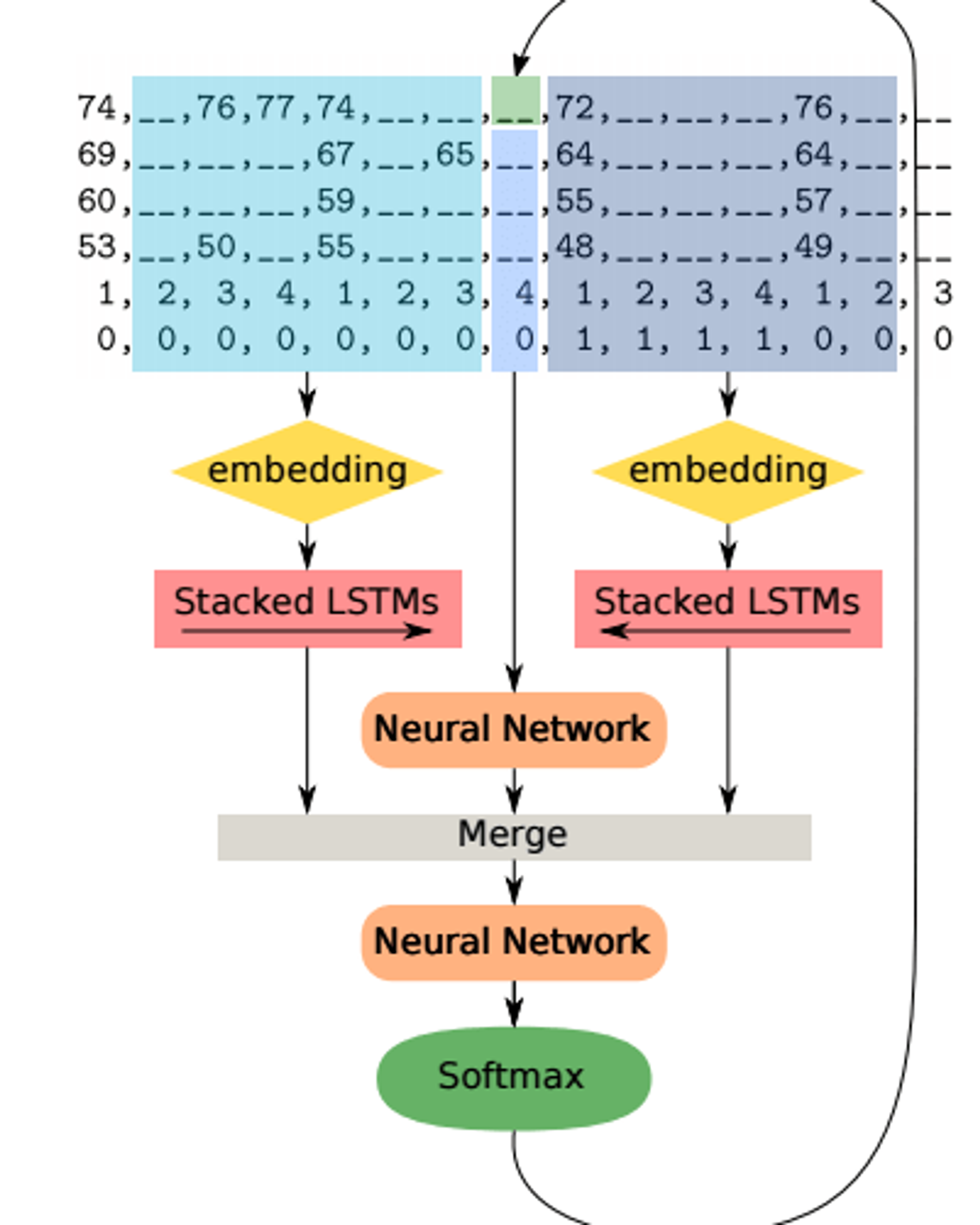
2016
Unsupervised Learning of 3D Structure from Images

2016
Aytar, Yusuf, Carl Vondrick, and Antonio Torralba, "Soundnet: Learning sound representations from unlabeled video.", Advances in neural information processing systems 29, pp892-900 (2016)

