
Tag: image
2024
アートを含まない学習データを学習したAIモデルをベースに、少数のアート作品の画像でLoRAを学習。きちんとそのアーティストの特徴を掴んだ画像が生成された。
Ren, Hui, Joanna Materzynska, Rohit Gandikota, David Bau, and Antonio Torralba. 2024. “Art-Free Generative Models: Art Creation Without Graphic Art Knowledge.” http://arxiv.org/abs/2412.00176.

2023
アーティストのスタイルが勝手に模倣されることを防ぐ Adversarial Example
Shan, Shawn, Jenna Cryan, Emily Wenger, Haitao Zheng, Rana Hanocka, and Ben Y. Zhao. 2023. “GLAZE: Protecting Artists from Style Mimicry by Text-to-Image Models.” arXiv [cs.CR]. arXiv. http://arxiv.org/abs/2302.04222.

2019
X線写真をコンテンツ画像に、同時代の同じ作家の絵をスタイル画像としてスタイルトランスファーをかける。美術史家などからその手法に対して強い批判も上がっている。
Bourached, A., & Cann, G. H. (2019). Raiders of the Lost Art. CrossTalk, 22(7–8), 35. https://doi.org/10.1525/9780520914957-028

2021
CLIPからオーディオ表現を抽出する手法であるWav2CLIPを提案。オーディオ分類・検索タスクで良好な結果を残す

2021
テキストと画像がどのくらいマッチしているかを定量化するモデル OpenAI CLIPを評価関数に用いて、進化戦略ESによって生成した抽象画
YINGTAO TIAN, DAVID HA. Modern Evolution Strategies for Creativity: Fitting Concrete Images and Abstract Concepts (2021)

2021
画像とテキストの関連性の高さを判定するモデルCLIPを用いて、生成される画像を最適化 → テキストの入力にあった画像が生成
OpenAI CLIP + Image Generation Models = CLIP art

2021
ライブラリをインストールしてたった二行で、存在しない人の顔画像が生成できるPythonライブラリ
random_faces

2020
様々なメディアのフレームを補間する – Depth-Aware Video Frame Interpolation
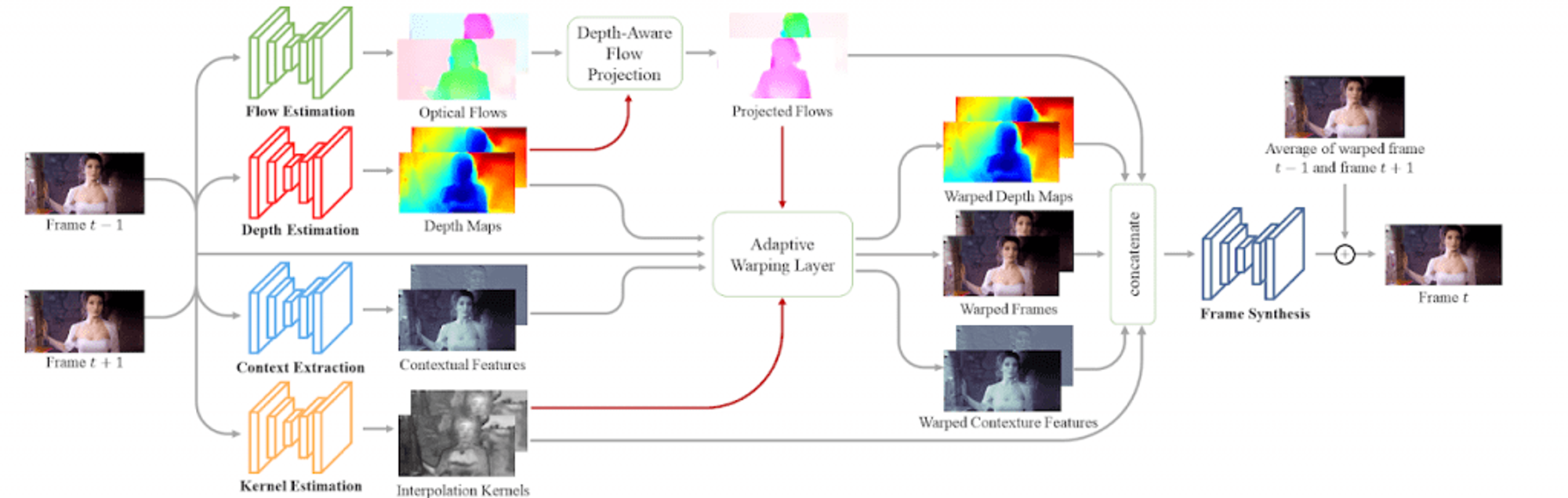
2019
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Stein- hardt, and Dawn Song. Natural adversarial examples. arXiv preprint arXiv:1907.07174, 2019.

2017
Neural 3D Mesh Renderer

2017
AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions


2017
Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression

2017
グラフィックデザインにおける各要素の重要性を可視化
グラフィックデザインにおける各要素の重要性を可視化 – Learning Visual Importance for Graphic Designs and Data Visualizations

2017
Penny, an AI to predict wealth from space

2017
料理の写真 ↔︎ 材料とレシピ
Learning Cross-modal Embeddings for Cooking Recipes and Food Images

2017
Chandrasekaran, Arjun, Devi Parikh, and Mohit Bansal. "Punny captions: Witty wordplay in image descriptions." arXiv preprint arXiv:1704.08224 (2017).


2017
Generating Videos with Scene Dynamics

2017
Forecasting Human Dynamics from Static Images

2017
絵を「描く」プロセスの模倣 – A Neural Representation of Sketch Drawings
絵を「描く」プロセスの模倣 – A Neural Representation of Sketch Drawings


2017
Seeing Invisible Poses: Estimating 3D Body Pose from Egocentric Video

2017
Photo Aesthetics Ranking Network with Attributes and Content Adaptation


2017
AutoHair: Fully Automatic Hair Modeling from A Single Image

2017
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks

2017
Using Deep Learning and Google Street View to Estimate the Demographic Makeup of the US


2017
ファッションの地理的および時系列的なトレンドをスナップ写真から解析するプロジェクト.
Abe, Kaori, et al., "Changing fashion cultures." arXiv preprint arXiv:1703.07920, (2017)

2015
Schifanella, Rossano, Miriam Redi, and Luca Maria Aiello, "An image is worth more than a thousand favorites: Surfacing the hidden beauty of flickr pictures.", Ninth International AAAI Conference on Web and Social Media, (2015)

2017
Deep Photo Style Transfer

2017
Learning to Generate Posters of Scientific Papers

2017
Faster-RCNNの拡張. ひとつのモデルで最小限の変更で物体検出、輪郭検出、人の姿勢の検出を高い精度で行う.
HE, Kaiming, et al., "Mask r-cnn", Proceedings of the IEEE international conference on computer vision, pp. 2961-2969, (2017)

2017
機械学習を用いたドローイングツール – AutoDraw
機械学習を用いたドローイングツール – AutoDraw

2016
Domenech, Arnau Pons, and Hartmut Ruhl. "An implicit ODE-based numerical solver for the simulation of the Heisenberg-Euler equations in 3+ 1 dimensions." arXiv preprint arXiv:1607.00253 (2016).

2017
the Robot Art competition
RobotArt – the Robot Art competition

2016
ファッション写真のデータセット – Large-scale Fashion (DeepFashion) Database

2017
LIU, Ziwei, et al., "Video frame synthesis using deep voxel flow", Proceedings of the IEEE International Conference on Computer Vision, pp. 4463-4471, (2017)
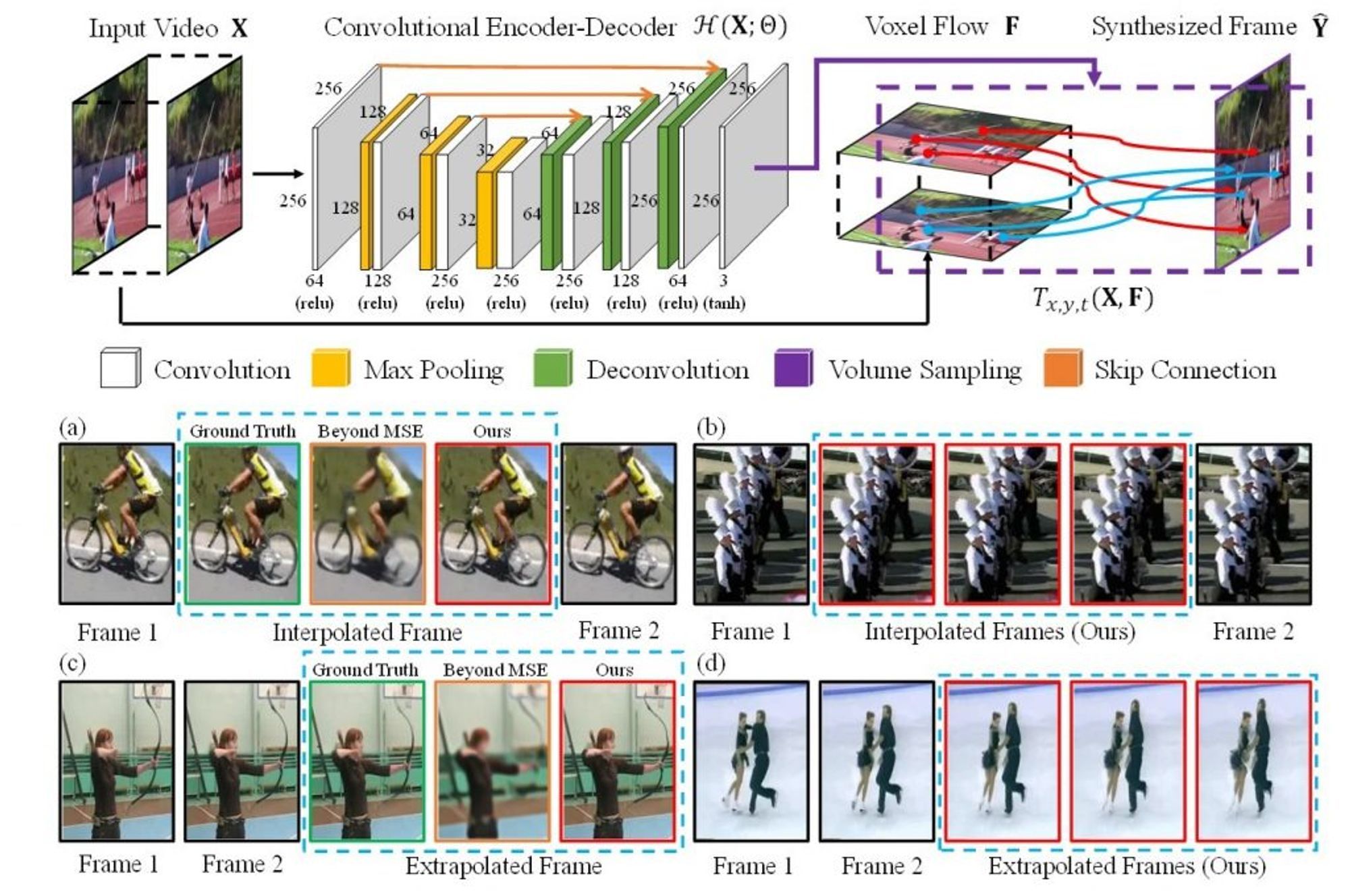
2017
YANG, Shuai, et al. "Awesome typography: Statistics-based text effects transfer", Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.7464-7473, (2017)
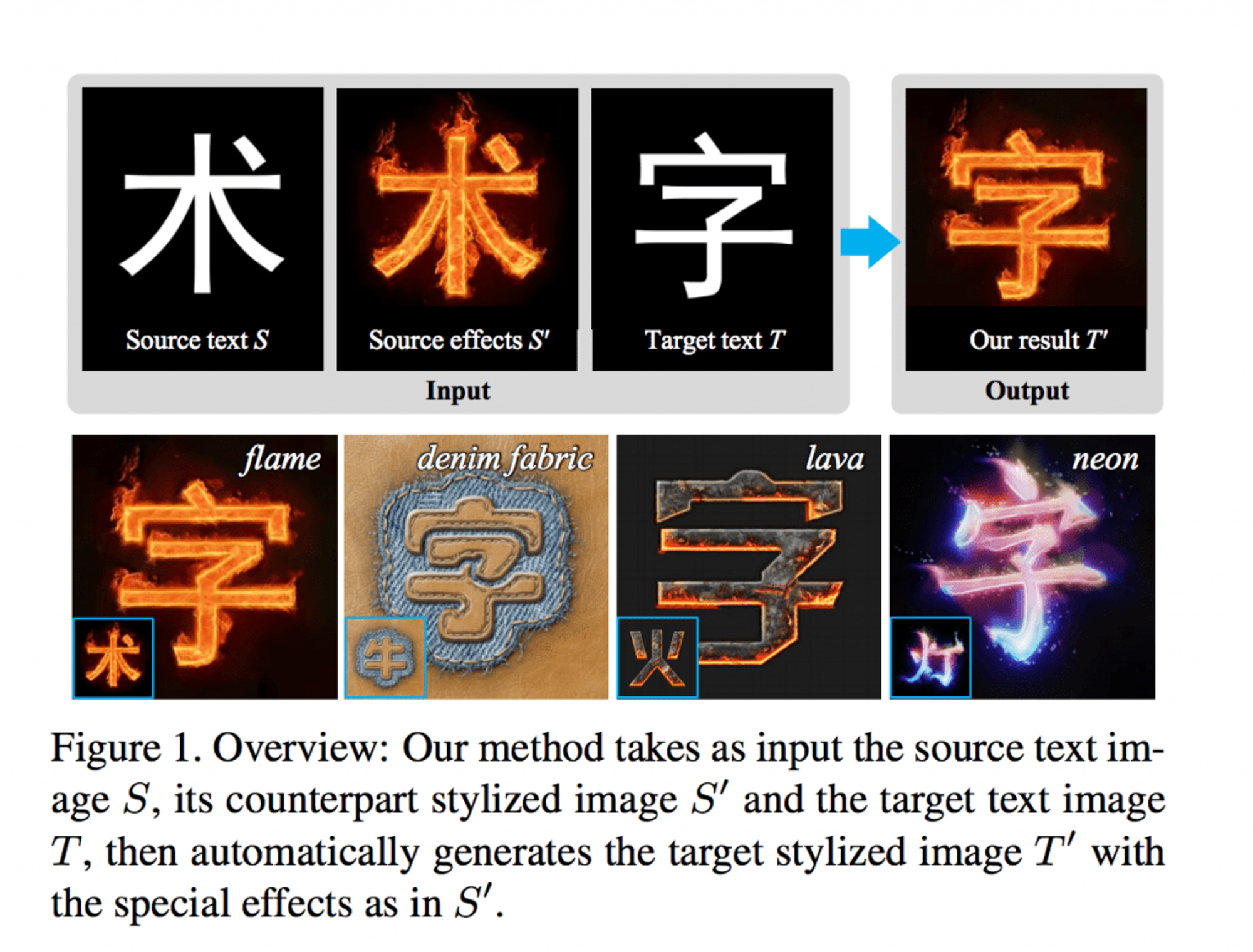
2017
Learning to Draw: Generating Icons and Hieroglyphs


