Tag: sound
2024
SunoやUdioで生成した楽曲を識別するためのフレームワーク
Rahman, Md Awsafur, Zaber Ibn Abdul Hakim, Najibul Haque Sarker, Bishmoy Paul, and S. Fattah. 2024. “SONICS: Synthetic or Not -- Identifying Counterfeit Songs,” August. http://arxiv.org/abs/2408.14080.

2019
Caillon, Antoine, and Philippe Esling. 2021. “RAVE: A Variational Autoencoder for Fast and High-Quality Neural Audio Synthesis.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/2111.05011.

2023
LLMと複数の音声合成モデルを駆使して、テキストプロンプトからスピーチ、音楽、SEなどを含む音のコンテンツ(ラジオドラマ、ポッドキャストのようなもの)を生成
Liu, Xubo, Zhongkai Zhu, Haohe Liu, Yi Yuan, Meng Cui, Qiushi Huang, Jinhua Liang, et al. 2023. “WavJourney: Compositional Audio Creation with Large Language Models.” arXiv [cs.SD]. arXiv. http://arxiv.org/abs/2307.14335.

2024
音楽生成AIは学習データをコピーしているだけではないか? 学習データと生成されたデータを比較。
Bralios, Dimitrios, Gordon Wichern, François G. Germain, Zexu Pan, Sameer Khurana, Chiori Hori, and Jonathan Le Roux. 2024. “Generation or Replication: Auscultating Audio Latent Diffusion Models.” In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1156–60. IEEE.

2023
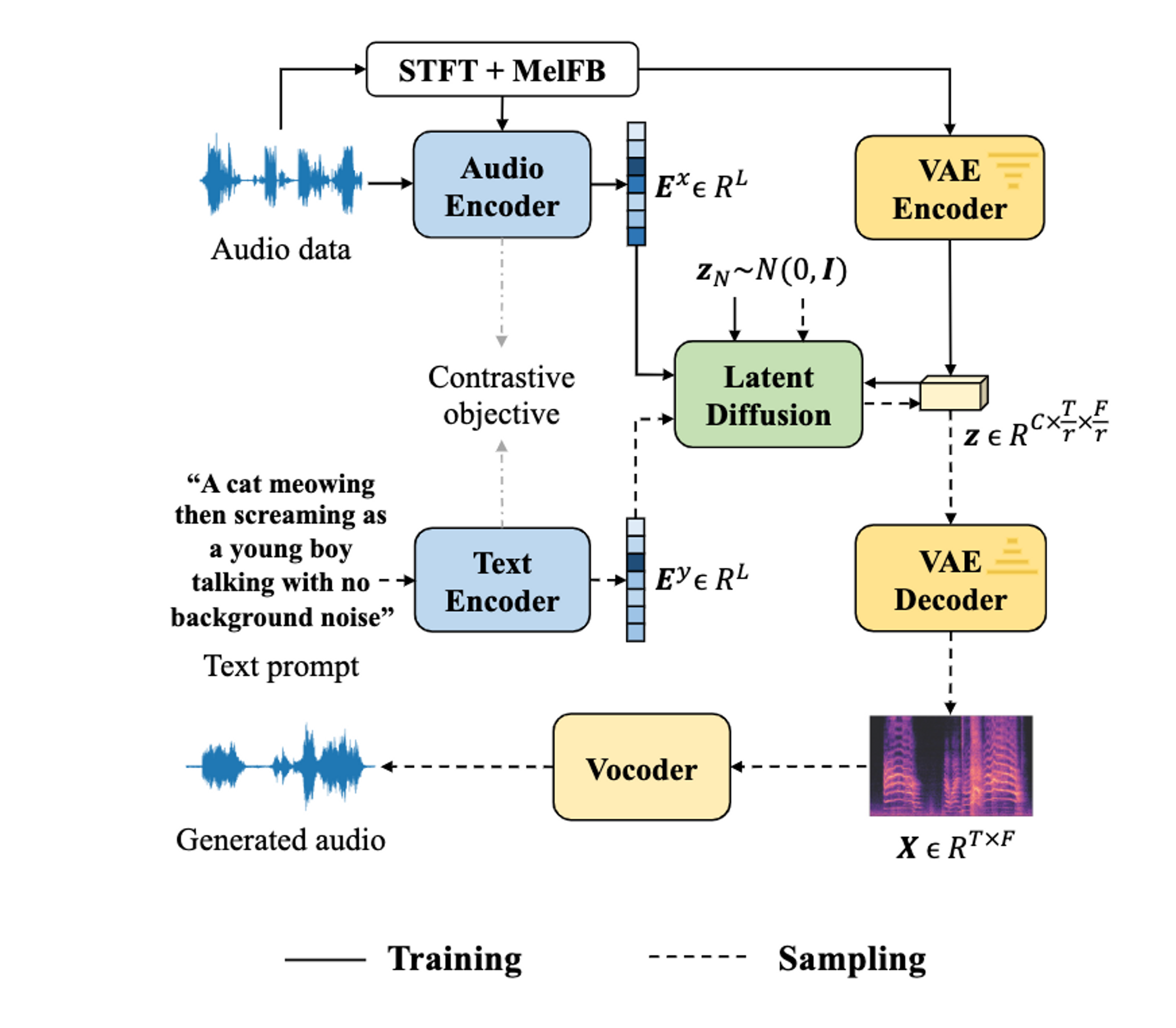
Liu, Haohe, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D. Plumbley. 2023. “AudioLDM: Text-to-Audio Generation with Latent Diffusion Models.” arXiv [cs.SD] . arXiv. http://arxiv.org/abs/2301.12503.
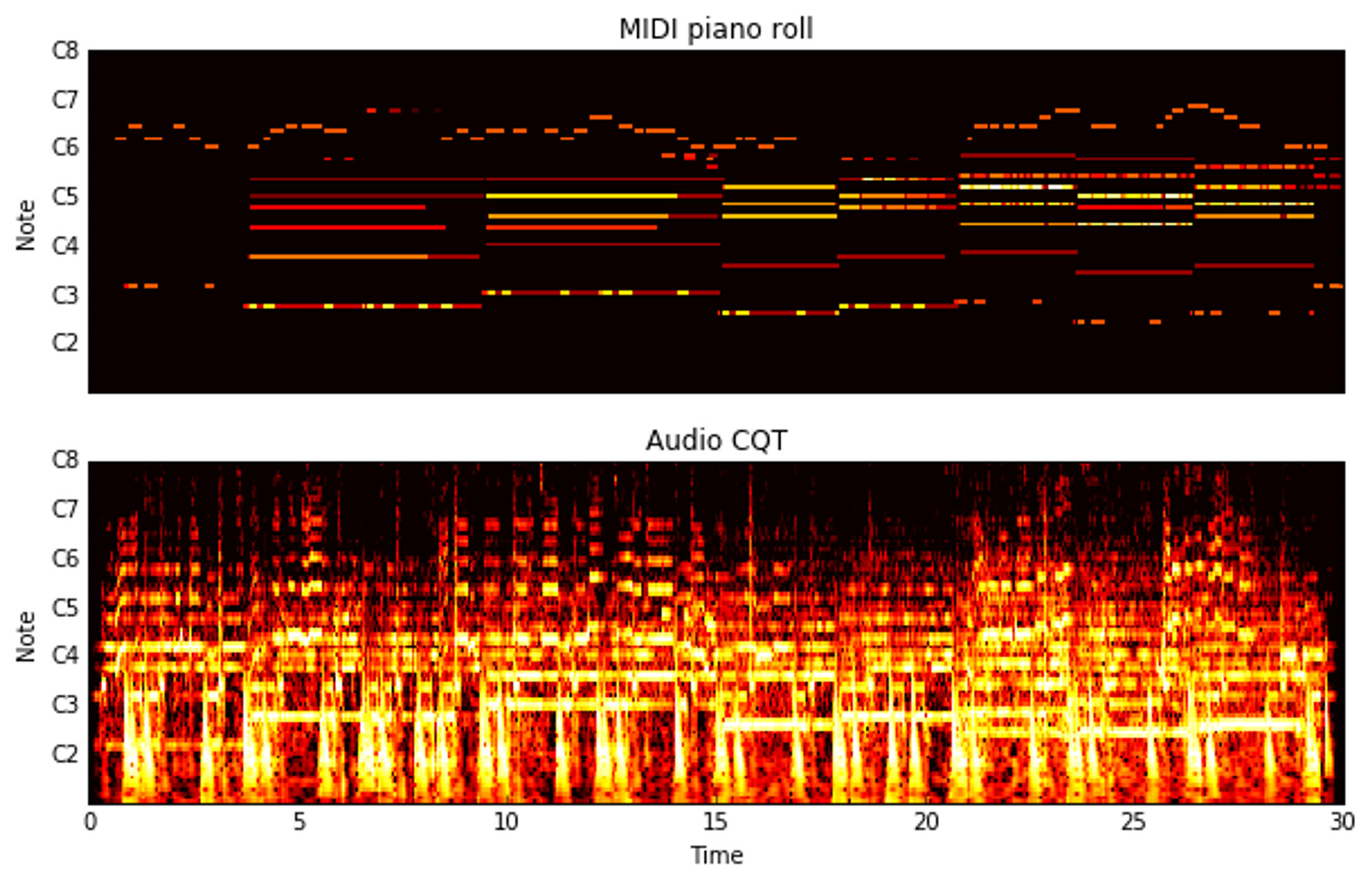
CLAPを用いることでText-to-AudioのSOTAを達成。オープンソース化されていて、すぐに試せるオンラインデモもあり!
2023
音源分離技術を使ってボーカルとそれに付随する伴奏を抽出。その関係を学習。Ground Truth (元々の曲に入ってた伴奏)には流石に劣るがそれに匹敵するクオリティの曲を生成できるようになった。
Donahue, Chris, Antoine Caillon, Adam Roberts, Ethan Manilow, Philippe Esling, Andrea Agostinelli, Mauro Verzetti, et al. 2023. “SingSong: Generating Musical Accompaniments from Singing.” arXiv [cs.SD] . arXiv. http://arxiv.org/abs/2301.12662.

2023
Latent Diffusionのアーキテクチャを利用して、テキストから音楽を生成するモデル
Schneider, Flavio, Zhijing Jin, and Bernhard Schölkopf. 2023. “Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion.” arXiv [cs.CL] . arXiv. http://arxiv.org/abs/2301.11757.

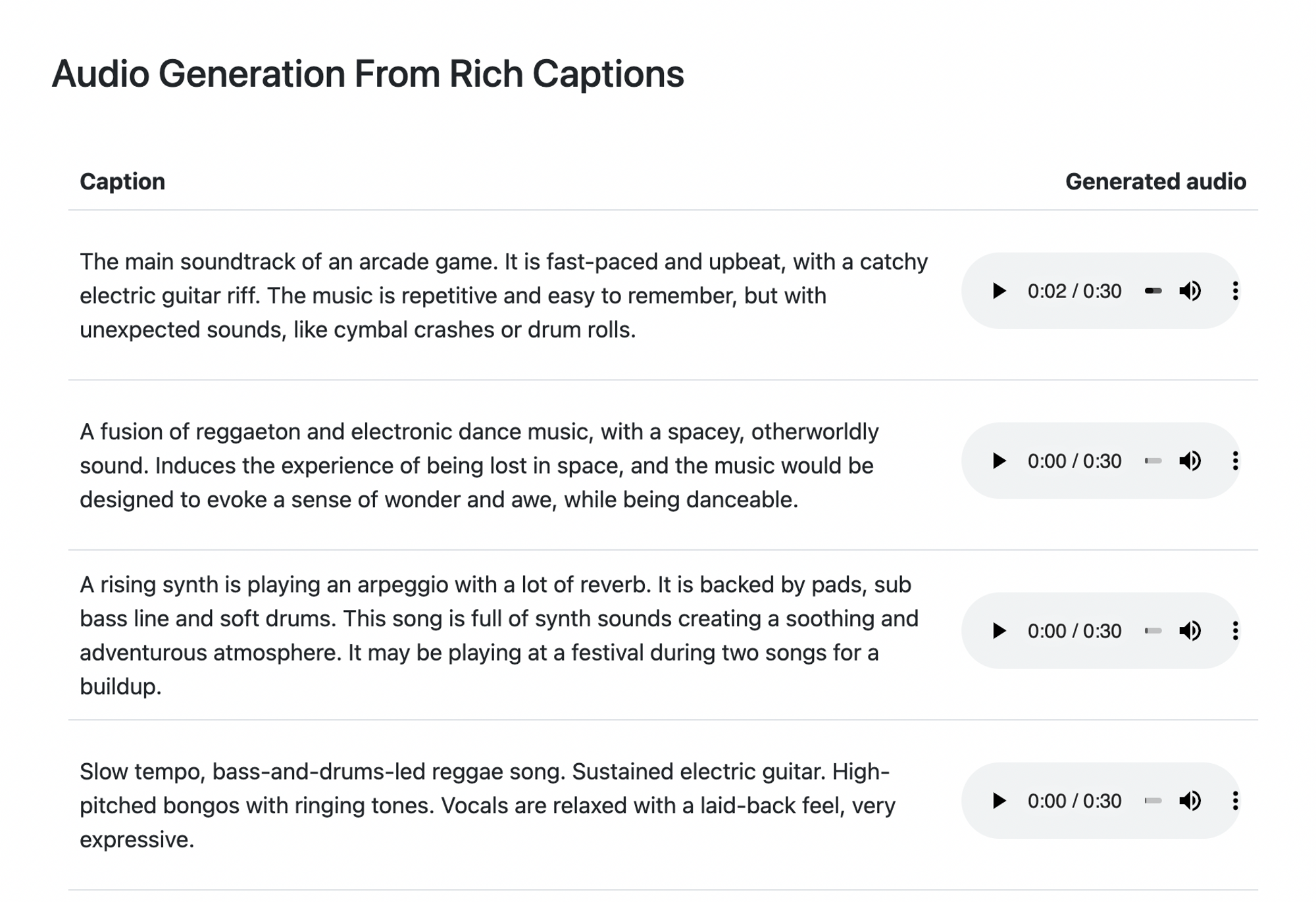
2023
“a calming violin melody backed by a distorted guitar riff” といったテキストから音楽がサウンドファイルとして生成される. Stable Diffusionの音楽版
Agostinelli, Andrea, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, et al. 2023. “MusicLM: Generating Music From Text.” arXiv [cs.SD] . arXiv. http://arxiv.org/abs/2301.11325.
2021
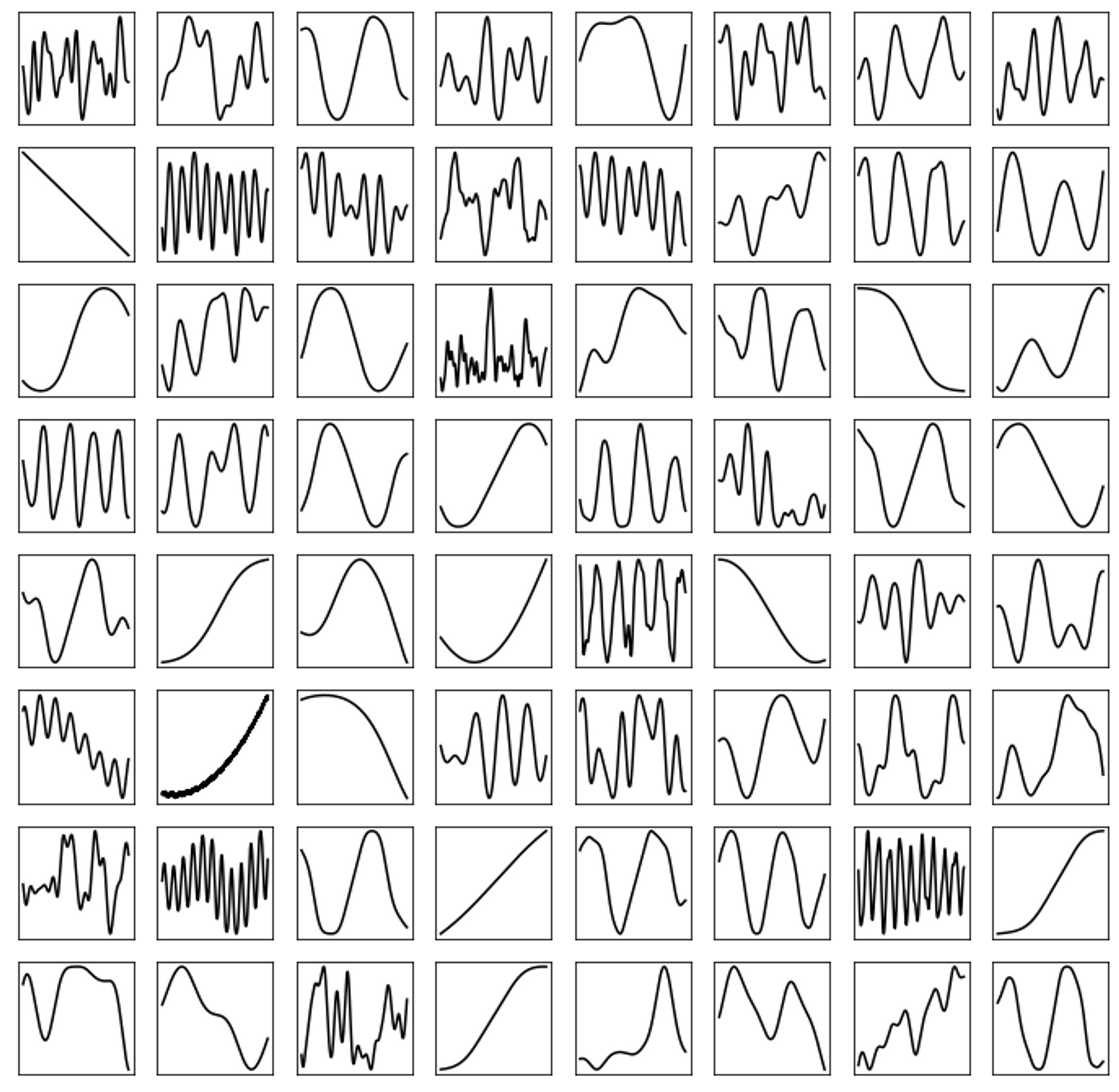
CPUでもサクサク動くのがポイント!
Hayes, B., Saitis, C., & Fazekas, G. (2021). Neural Waveshaping Synthesis.
2021
CLIPからオーディオ表現を抽出する手法であるWav2CLIPを提案。オーディオ分類・検索タスクで良好な結果を残す

2021
なんと総時間は約126年分!! データセットを生成するためにpytorch上に実装された、GPUに最適化されたモジュラーシンセ torchsynthも合わせて公開。
Turian, J., Shier, J., Tzanetakis, G., McNally, K., & Henry, M. (2021). One Billion Audio Sounds from GPU-enabled Modular Synthesis.
2021
Google Magentaチームの最新のプロジェクト。2020年に発表した DDSP: Differentiable Digital Signal Processing を使って、絵筆のストロークを楽器音に変えている。筆で描くように音を奏でることができる。
Paint with Music - Google Magenta

2020
GANやAutoEncoderが使われている。2021年のアルスエレクトロニカ Digital Musics & Sound Art 部門のゴールデンニカ(最優秀賞)。
Alexander Schubert - Convergence (2020)

2019
Ramires, A., Chandna, P., Favory, X., Gómez, E., & Serra, X. (2019). Neural Percussive Synthesis Parameterised by High-Level Timbral Features. ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings, 2020-May, 786–790. Retrieved from http://arxiv.org/abs/1911.11853
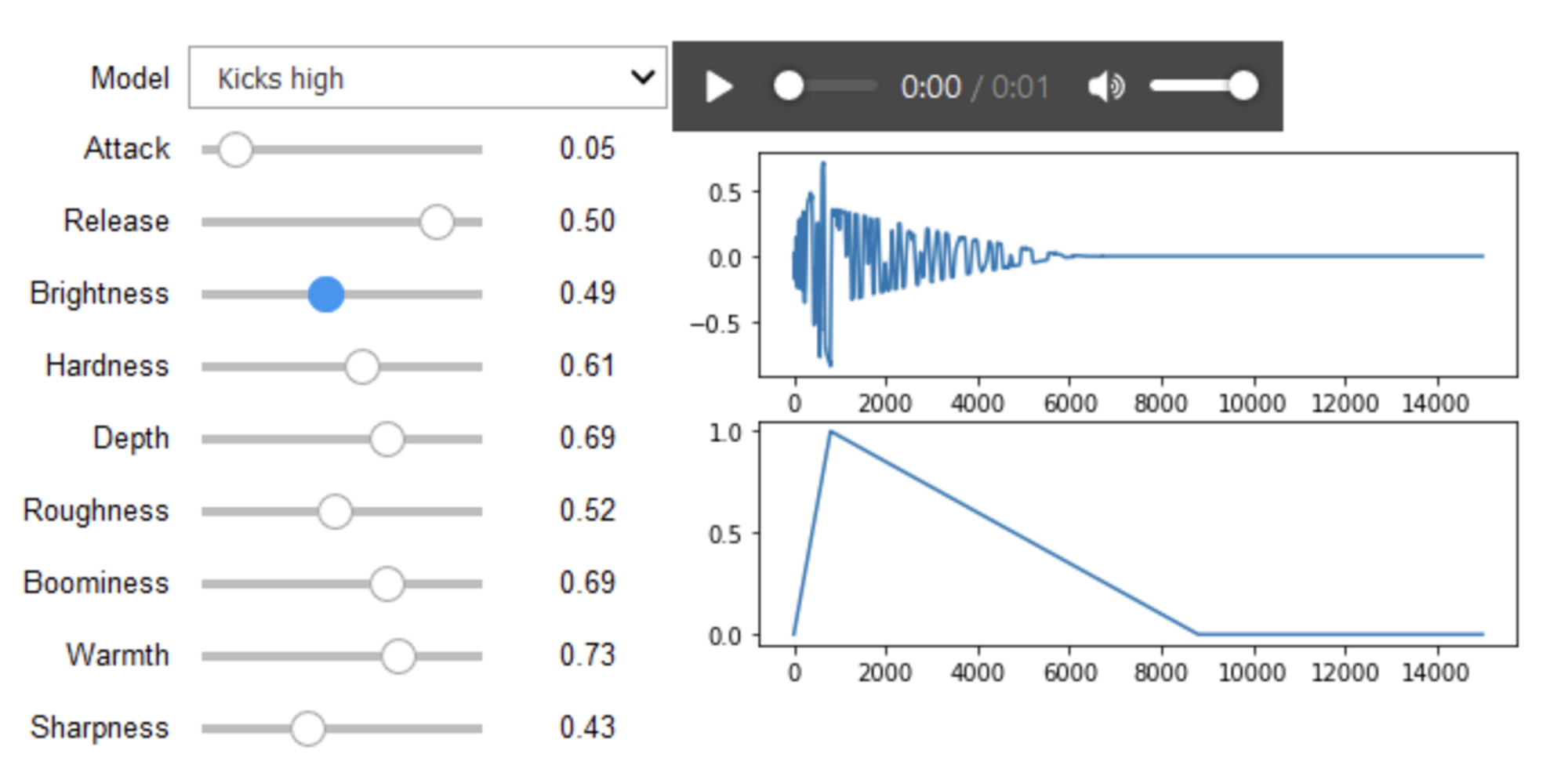
2017
WaveNetの仕組みを使ったAutoencoderで、楽器の音の時間方向の変化も含めて、潜在空間にマッピング → 潜在ベクトルから楽器の音を合成する。この研究で使った多数の楽器の音を集めたデータセット NSynth を合わせて公開。
Engel, J. et al. (2017) ‘Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders’. Available
https://github.com/MTG/essentia
https://github.com/MTG/essentia
Dmitry Bogdanov, et al. 2013. ESSENTIA: an open-source library for sound and music analysis. In Proceedings of the 21st ACM international conference on Multimedia (MM '13). Association for Computing Machinery, New York, NY, USA, 855–858. DOI:https://doi.org/10.1145/2502081.2502229

2020
ドラム、パーカションのワンショットを集めたデータセット
António Ramires, Pritish Chandna, Xavier Favory, Emilia Gómez, & Xavier Serra. (2020). Freesound One-Shot Percussive Sounds (Version 1.0) [Data set]. Zenodo. http://doi.org/10.5281/zenodo.3665275

2021
環境音の識別モデルの学習のためのData Augmentation手法の提案
Madhu, A. and K, S. (2021) ‘EnvGAN: Adversarial Synthesis of Environmental Sounds for Data Augmentation’.

2021
Google MagentaのDDSPをリアルタイムに動かせるプラグイン
Francesco Ganis, Erik Frej Knudesn, Søren V. K. Lyster, Robin Otterbein, David Südholt, Cumhur Erkut (2021)

2020
グラニュラーシンセシスのGrain(音の粒)をVAEを使って生成しようという試み。Grainの空間の中での軌跡についても合わせて学習。
Hertzmann, A. (2020) ‘Visual indeterminacy in GAN art’, Leonardo. MIT Press Journals, 53(4), pp. 424–428. doi: 10.1162/LEON_a_01930.

2018
Audio-Visual Scene Analysis with Self-Supervised Multisensory Features

2018
Synthesizing Audio with Generative Adversarial Networks

2018
Visual to Sound: Generating Natural Sound for Videos in the Wild

2017
Performance RNN: Generating Music with Expressive Timing and Dynamics

2017
Deep Cross-Modal Audio-Visual Generation


2017
The Infinite Drum Machine : Thousands of everyday sounds, organized using machine learning


2017
Convolutional Recurrent Neural Networks for Bird Audio Detection