Tag: visual
@June 18, 2024 9:30 PM (GMT+2)
. . "Artists on a Decade of AI Evolution: An Interview Study of Affordances, Culture, and Artistic Practice with Machine Learning."

2024
アートを含まない学習データを学習したAIモデルをベースに、少数のアート作品の画像でLoRAを学習。きちんとそのアーティストの特徴を掴んだ画像が生成された。
Ren, Hui, Joanna Materzynska, Rohit Gandikota, David Bau, and Antonio Torralba. 2024. “Art-Free Generative Models: Art Creation Without Graphic Art Knowledge.” http://arxiv.org/abs/2412.00176.

2021
画像とテキストがどれくらいマッチしているかを定量化するCLIPモデルを用いて、要素画像の配置を最適化。入力されたテキストにあったコラージュ画像を生成するシステム
CLIP-guided collage image optimization using Evolutionary Strategy

2021
CLIP+VQ-GANの仕組みを活用
Botto Project

2020
GANが生成する画像の「●●ぽいけど、なんか違う...」という「不確定性」に着目し、現代アートの特徴との比較を行った上で、今後のGANアートの将来像を探る。
Hertzmann, A. (2020) ‘Visual indeterminacy in GAN art’, Leonardo. MIT Press Journals, 53(4), pp. 424–428.

2019
スパースなTransformerの仕組みで計算量を抑える
Child, R. et al. (2019) ‘Generating Long Sequences with Sparse Transformers’, arXiv. arXiv. Available at: http://arxiv.org/abs/1904.10509 (Accessed: 29 January 2021).

2021
8万枚の絵画にクラウドソーシングで44万の言語情報を付加。
ArtEmis: Affective Language for Visual Art

普通の画像認識モデルのようなオブジェクトの識別に加えて、カメラのアングルやフォーカスの当て方(ソフトフォーカス...)、撮影された時間帯(夕方、朝焼け)、場所などをタグ付け
CinemaNet by Anton Marini(vade), Rahul Somani

2019
Han-Hung Lee, Da-Gin Wu, and Hwann-Tzong Chen, "Stylizing Audio Reactive Visuals", NeurlPS2019, (2019)

2020
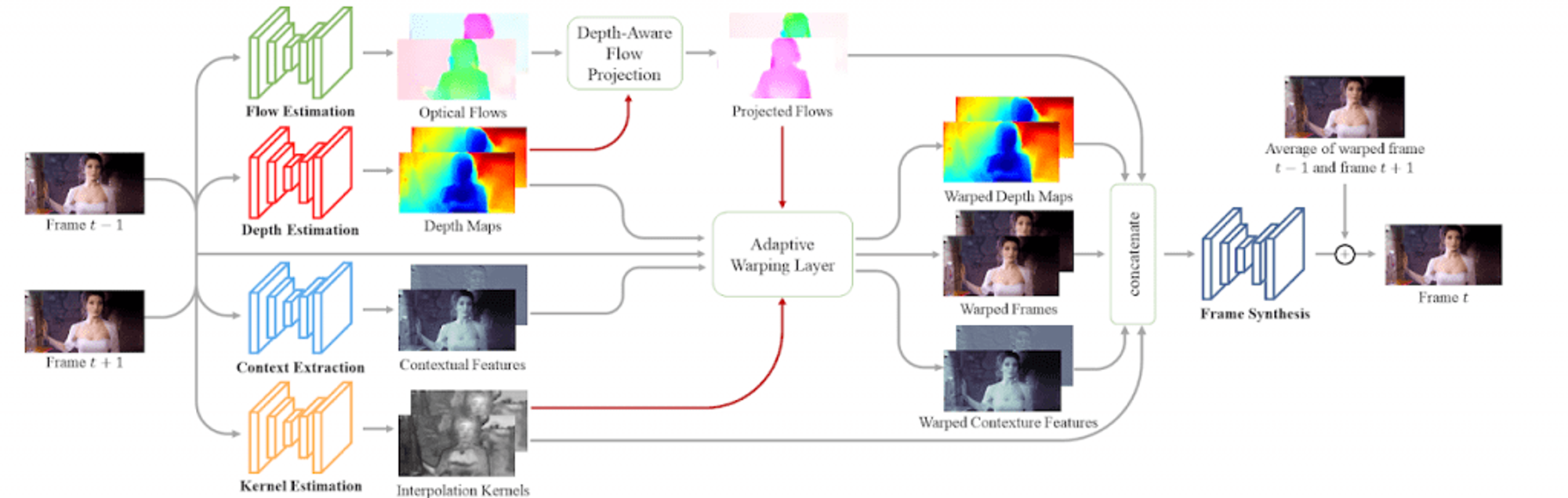
様々なメディアのフレームを補間する – Depth-Aware Video Frame Interpolation
2018
Audio-Visual Scene Analysis with Self-Supervised Multisensory Features

2018
Visual to Sound: Generating Natural Sound for Videos in the Wild

2017
Neural 3D Mesh Renderer

2017
AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions


2017
Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression

2017
The iNaturalist Challenge 2017 Dataset

2017
CAN: Creative Adversarial Networks Generating “Art” by Learning About Styles and Deviating from Style Norms

2017
Interactive 3D Modeling with a Generative Adversarial Network

2017
Deep Cross-Modal Audio-Visual Generation


2017
適切なフォントの組み合わせを生成 – Fontjoy
適切なフォントの組み合わせを生成 – Fontjoy

2017
Generating Videos with Scene Dynamics

2017
Forecasting Human Dynamics from Static Images

2017
Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis

2017
The Infinite Drum Machine : Thousands of everyday sounds, organized using machine learning

2017
Seeing Invisible Poses: Estimating 3D Body Pose from Egocentric Video

2017
Photo Aesthetics Ranking Network with Attributes and Content Adaptation

2017
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks

2017
Using Deep Learning and Google Street View to Estimate the Demographic Makeup of the US

2017
Changing Fashion Cultures

2017
Deep Photo Style Transfer

2017
DeepWarp: Photorealistic Image Resynthesis for Gaze Manipulation

2017
DeepDreamを用いたのドローイングツール- DreamCanvas
DeepDreamを用いたのドローイングツール- DreamCanvas

2017
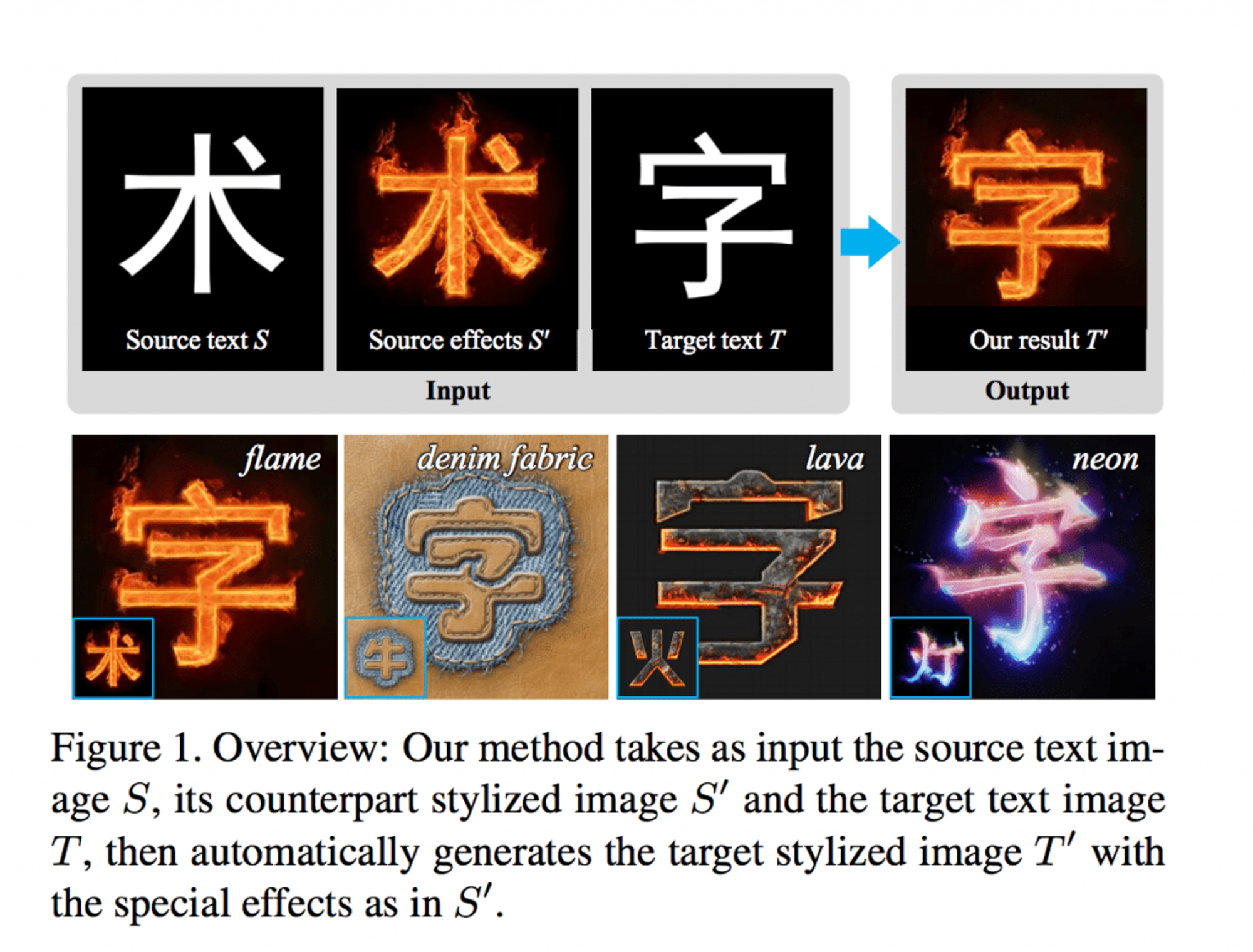
YANG, Shuai, et al. "Awesome typography: Statistics-based text effects transfer", Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.7464-7473, (2017)
2017
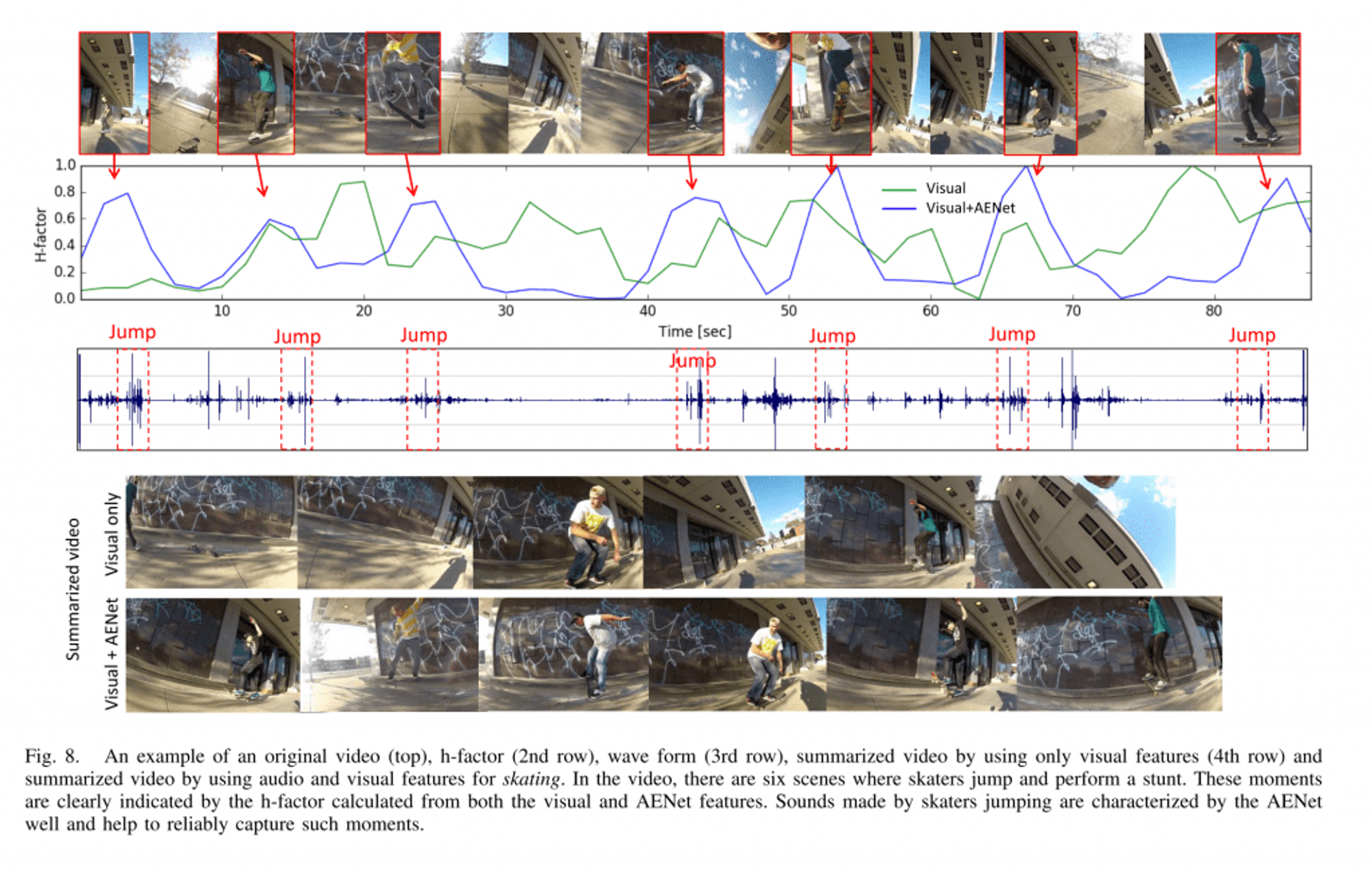
AENet: Learning Deep Audio Features for Video Analysis